
In this Tekin Radar deep-dive, we dissect OpenAI's custom silicon project codenamed "Titan." Built on TSMC's 3nm node with a landmark $10B Broadcom networking deal, the Titan chip targets the Inference layer to break Nvidia's GPU monopoly. We analyze the Triple Alliance strategy, market implications, the upcoming Titan 2 on A16 process, and OpenAI's roadmap to full vertical integration through 2029.
Tekin Radar: The Silicon Earthquake in the Valley; How OpenAI’s Custom “Titan” Chip Will Break Nvidia’s Monopoly in 2026
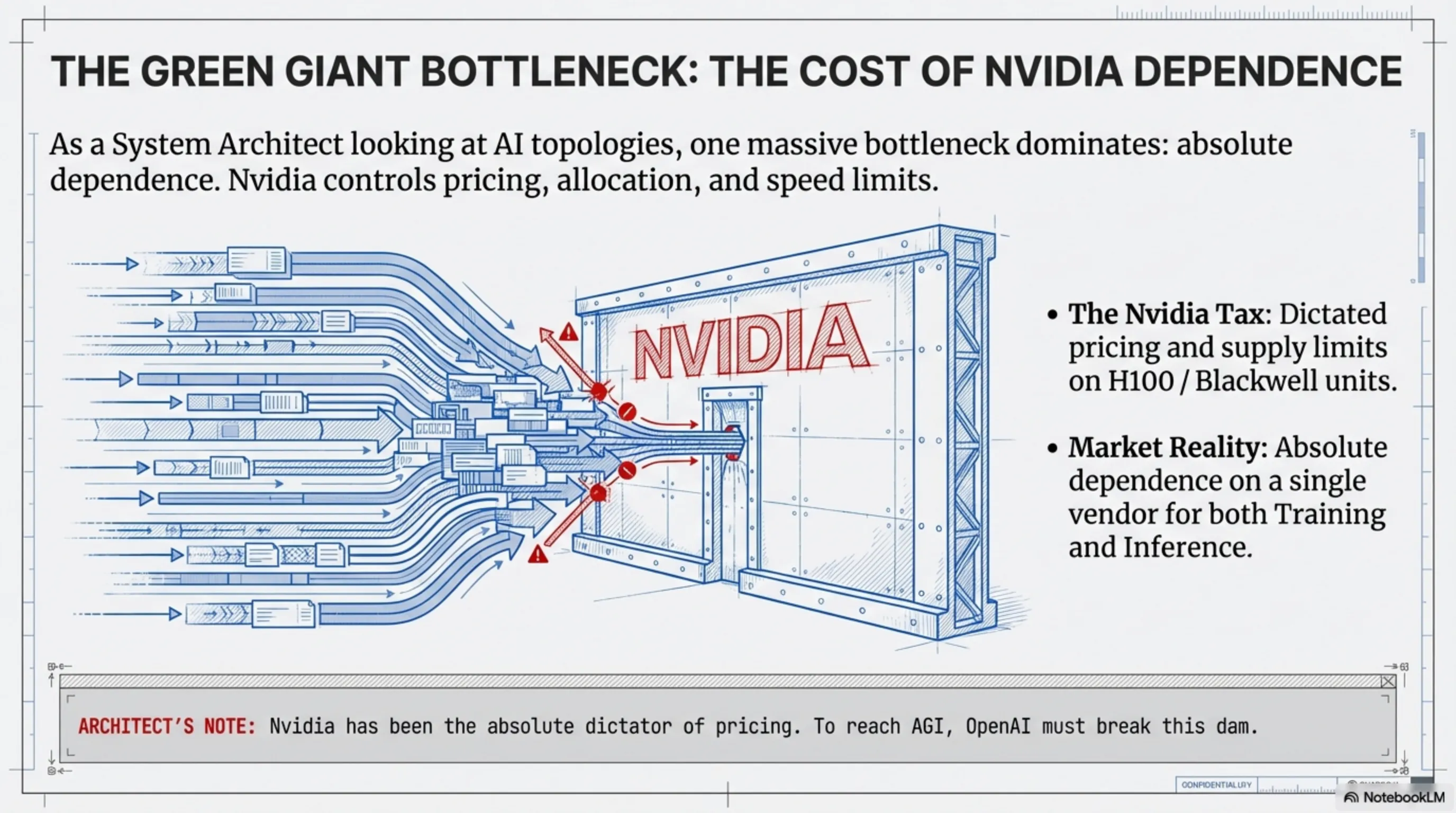
As a System Architect, when looking at AI hardware topologies, one massive, bloodsucking bottleneck always dominates the landscape: absolute dependence on the Green Giant, Nvidia. However, today, in early March 2026, deep leaks from the heart of Silicon Valley reveal a tectonic shift. OpenAI, the creator of ChatGPT and the undisputed global leader in artificial intelligence, has decided it can no longer remain merely a software consumer. Partnering with silent hardware behemoths Broadcom and TSMC, they are forging a custom piece of silicon codenamed Titan, aimed at permanently rewriting the rules of computational infrastructure. This isn't just an economic maneuver to reduce astronomical API costs; it is a strategic declaration of war for absolute hardware sovereignty. We are entering an era where the architects of Artificial General Intelligence (AGI) have realized that without direct control over the bare metal of processors, they will never reach their ultimate goal. In this deep, analytical dive, we will dissect the hidden architecture of this chip, the backstage strategy with Broadcom, and the seismic consequences this technological shift will have on Nvidia's future and the entire AI ecosystem at the lowest system layers.
1. Project Titan: Dissecting OpenAI's Custom Silicon on TSMC’s 3nm Lithography
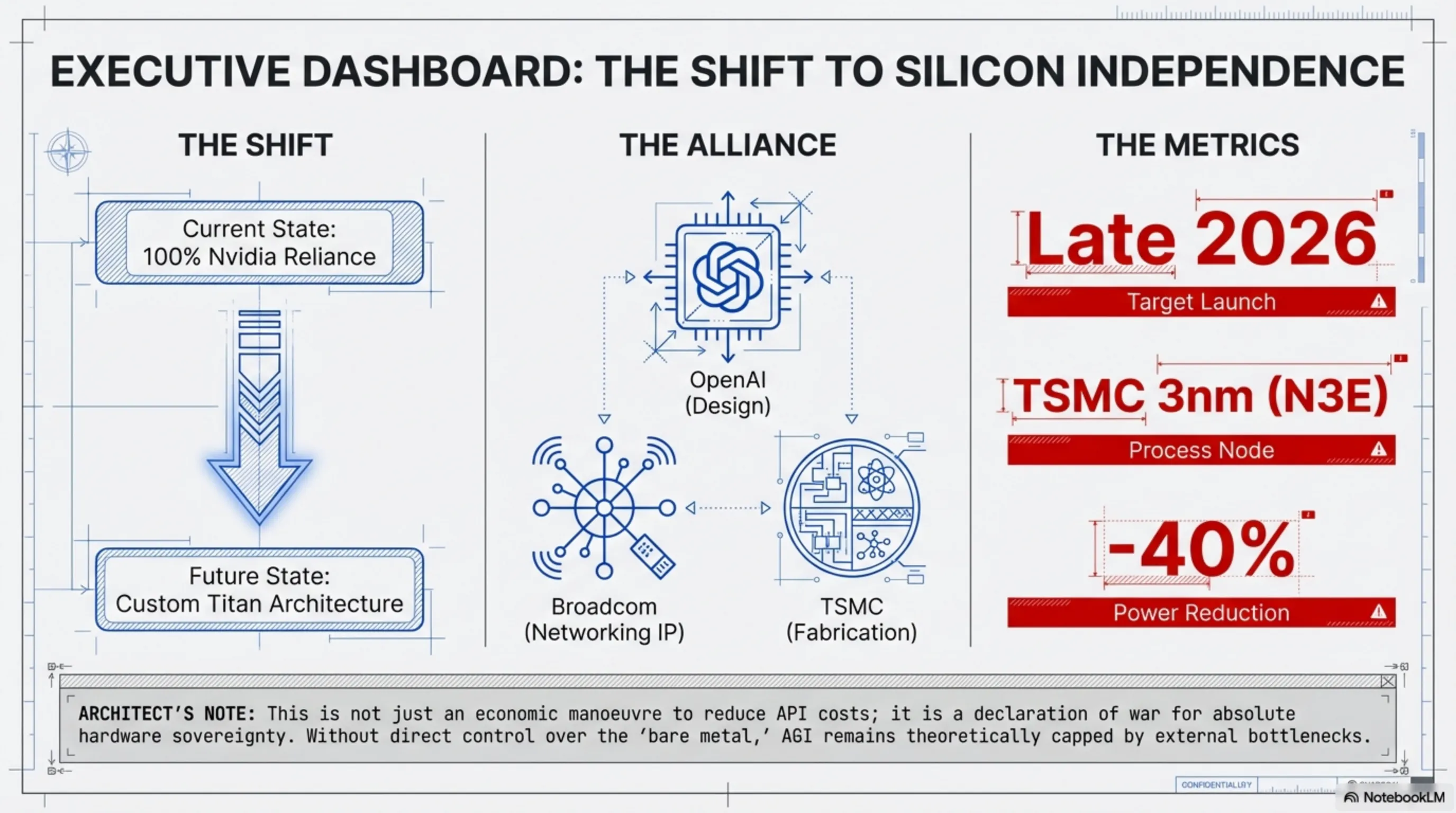
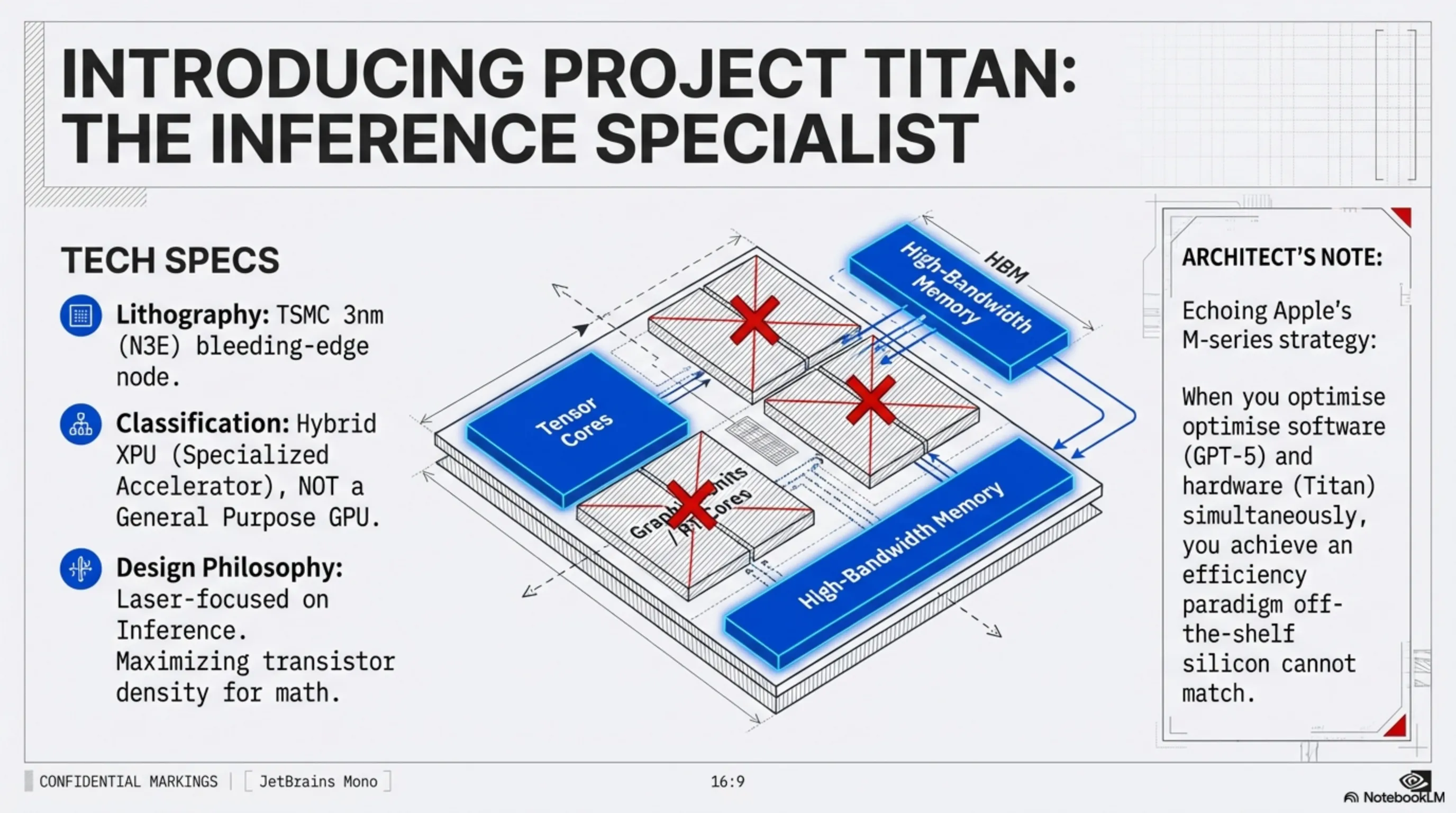
Developing a custom chip from scratch to the tape-out stage typically requires billions of dollars in capital and years of grueling R&D. Armed with Microsoft's unprecedented investments and bottomless revenue streams, OpenAI has accelerated through this treacherous path at lightning speed. The Titan chip, which whispers suggest is entering the production lines of TSMC's bleeding-edge 3-nanometer (N3E) node, is not a general-purpose processor like a GPU; rather, it is a specialized accelerator—a hybrid XPU—laser-focused on Inference processing.
- Targeted Architecture: Nvidia's GPUs, such as the H100 or the newer Blackwell series, are monsters engineered for the brutal mathematics of "Training" massive foundational models. But once a model is trained, answering millions of concurrent user queries per second requires efficient inference power. Titan is built explicitly for this bottleneck. The chip strips away unnecessary graphical processing units and dedicates all of its expensive 3nm transistors to specialized Tensor Cores and colossal memory bandwidth designed purely for real-time inference.
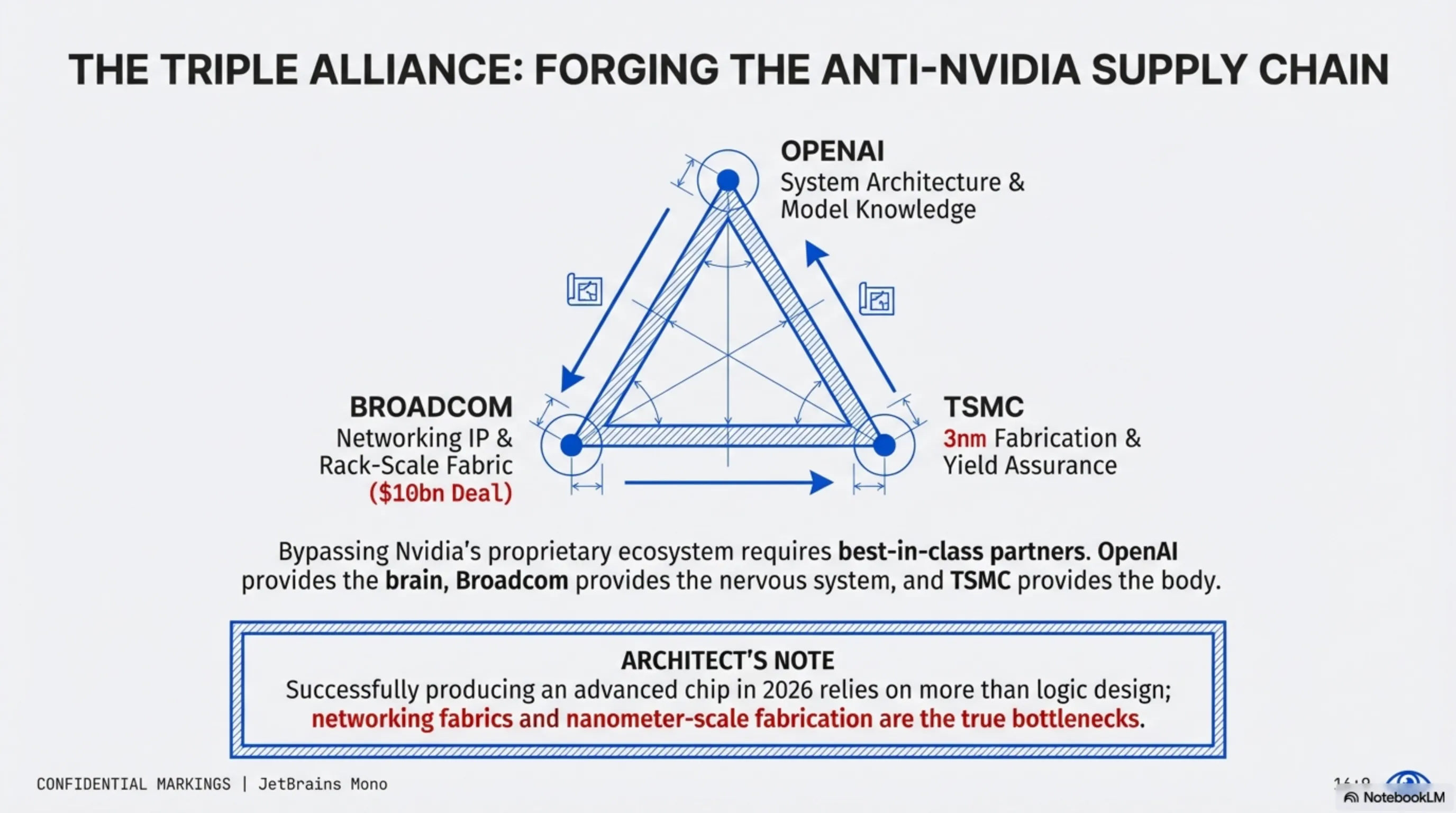
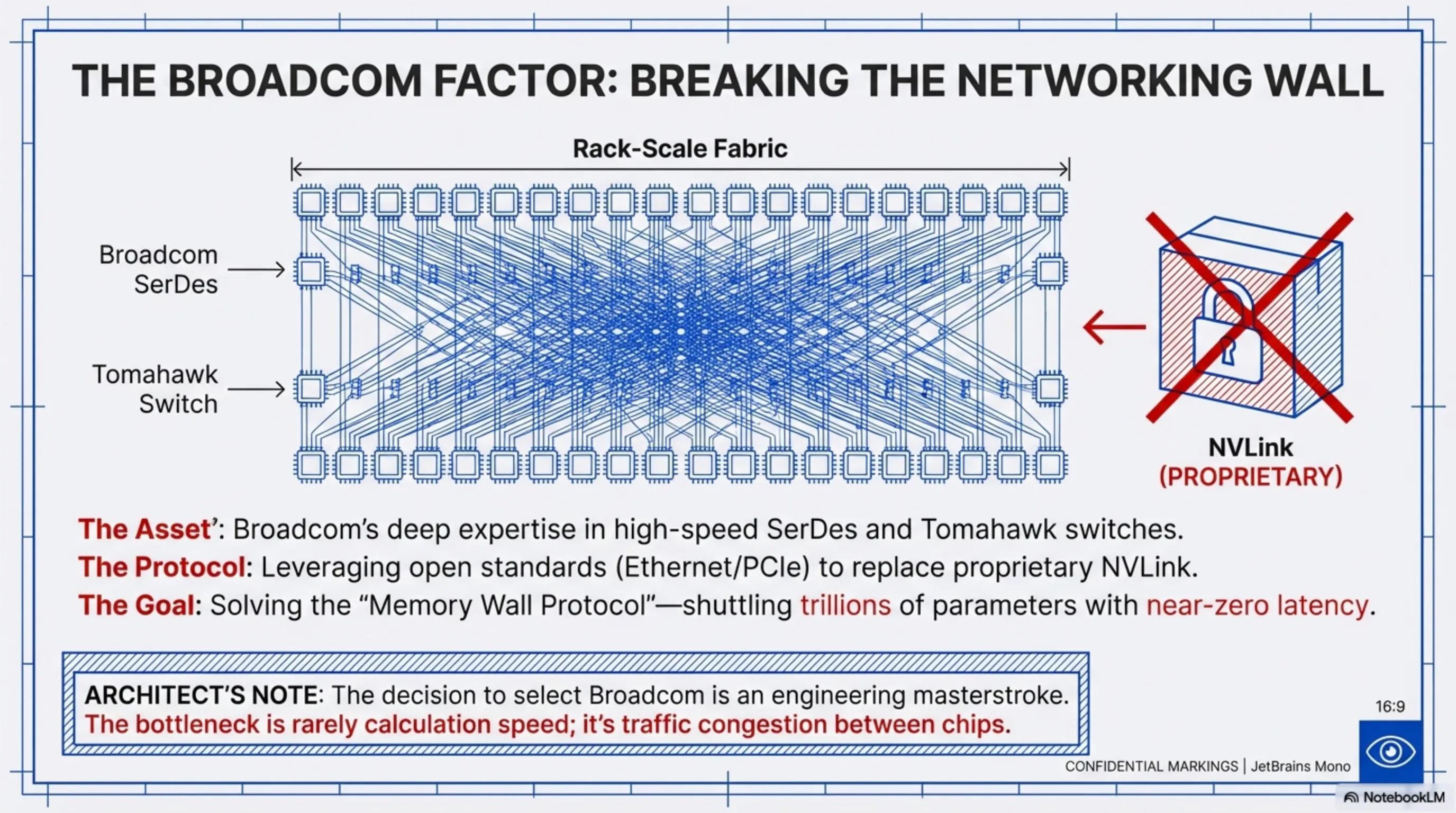
- The $10 Billion Broadcom Alliance: This is the turning point of the narrative. OpenAI alone lacked the deep expertise required to build high-speed inter-chip networking fabrics. Enter Broadcom—the undisputed king of networking chips and high-speed data center switches. Having reportedly secured a historic contract worth over $10 billion, Broadcom has stepped onto the battlefield. Broadcom’s task is to architect the Rack-scale Fabric, ensuring that thousands of Titan chips can communicate seamlessly with near-zero latency. This directly challenges Nvidia’s proprietary NVLink ecosystem.
- Drastic Power Reduction: At the system architecture layer, when an ASIC is optimized for a singular mathematical objective (e.g., FP8 or INT4 matrices used in AI inference), power consumption plummets dramatically. It is projected that Titan will reduce power draw in OpenAI’s data centers by up to 40% compared to traditional GPUs for inference—translating to billions saved in electricity and cooling costs at their massive current scale.
System Architect Analysis:
OpenAI's foray into the silicon club echoes Apple's strategy with the M-series chips (Apple Silicon). When you possess absolute control over the simultaneous optimization of software (GPT models) and hardware (Titan), you achieve an efficiency paradigm that no off-the-shelf hardware can possibly deliver. This means OpenAI can run its most potent models (like GPT-5 and beyond) at a fraction of competitors' costs, granting them an unbeatable gross margin in the AI services market. This chip is the key variable to OpenAI's independence.
.webp)
2. Why Inference? The Brilliant Escape from the Nvidia "Training" War
In the realm of AI hardware, there are two distinct battlefronts: the "Training" front, which requires precise double-precision floating-point calculations and massive, hyper-fast memory pools; and the "Inference" front, which relies heavily on latency minimization and data stream throughput. OpenAI’s strategy here is both brilliant and deeply pragmatic.
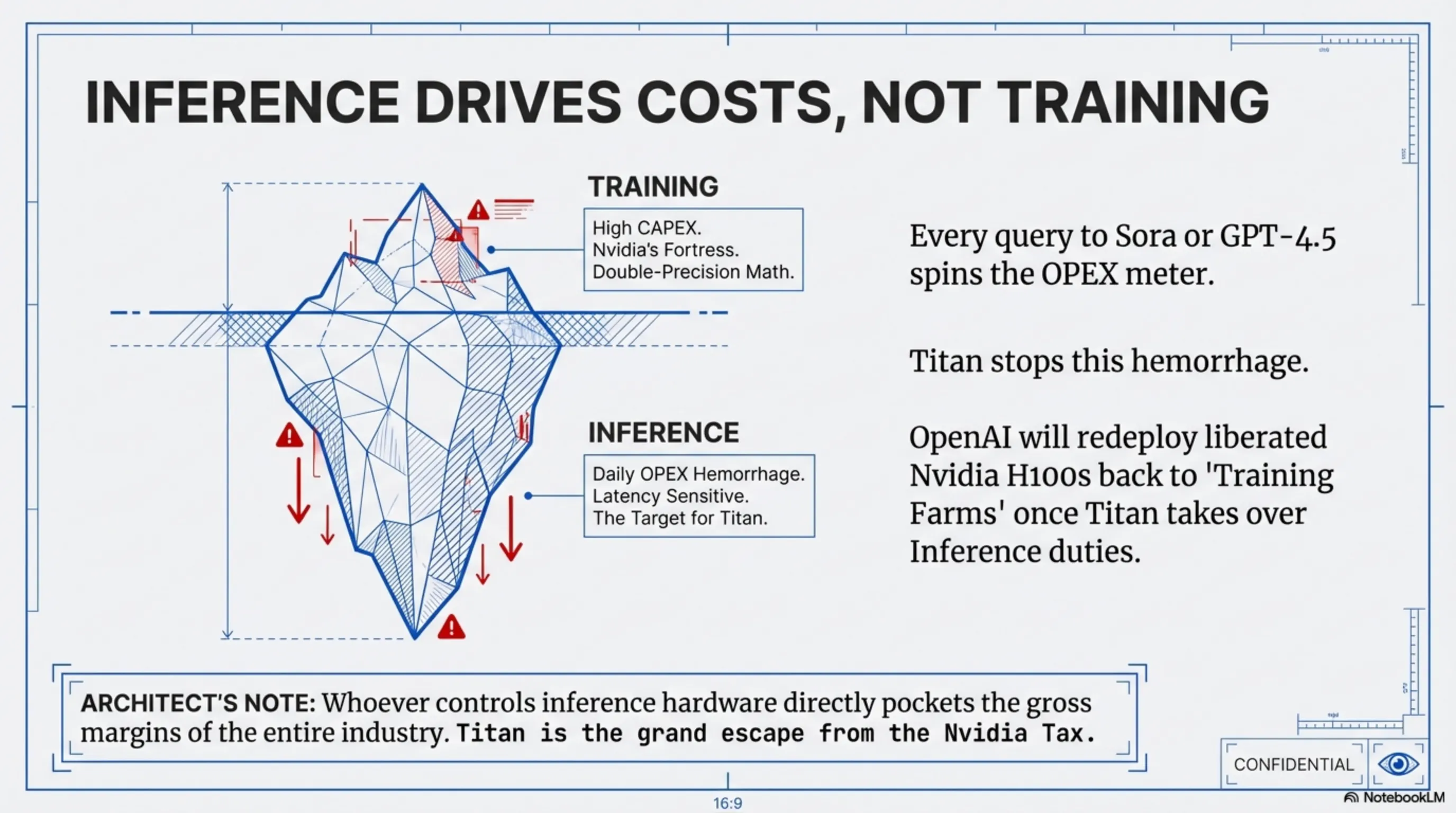
In the domain of model training processors (like the Blackwell and Hopper architectures), Nvidia has constructed an impenetrable fortress known as the CUDA software ecosystem. Breaking this dam, even for a juggernaut like OpenAI, is virtually impossible in the short term. Therefore, OpenAI has cleverly evaded direct confrontation with Nvidia on the training battlefield. Next-generation foundational models will continue to be trained on massive Nvidia GPU clusters. But where is the real money and the highest power draw happening? Answer: When those models go live and start processing hundreds of millions of daily user requests.
- The OPEX Hemorrhage: Sam Altman knows perfectly well that every time a user requests a video generation from Sora or asks GPT-4.5 to debug a complex programming puzzle, a massive operational expenditure (OPEX) meter turns over. By replacing expensive Nvidia GPUs with cheaper, hyper-efficient Titan chips at the inference layer, OpenAI can drastically slash its running OPEX.
- Freeing Strategic Resources: By offloading inference workloads to Titan-equipped servers, highly capable Nvidia hardware (H100s and B200s) is freed up. OpenAI will rapidly redeploy these liberated graphics cards back into their Training Farms, accelerating the development engine for GPT-5 and future AGI architectures. This is an elite-level optimization in Resource Allocation Architecture.
- Reducing Nvidia's Leverage: Until now, Nvidia has been the absolute dictator of pricing and the speed limit on AI company growth. Now, armed with Titan, OpenAI gains a massive negotiation lever regarding the pricing of training processors with both Nvidia and AMD. When you are the market's largest customer and you prove you can build your own bespoke silicon, vendors are forced to offer drastically steeper discounts.
"In the economics of the AI lifecycle, model training is merely the tip of the iceberg. The overwhelming mass of this iceberg hidden underwater is the Inference phase. Whoever controls inference hardware directly pockets the gross margins of the entire industry. The Titan chip is OpenAI’s grand escape from the Nvidia Tax." - System Architect Analytical Deep Dive
3. The Triangle Power Alliance: OpenAI, Broadcom, and TSMC vs. Nvidia's Proprietary Architecture
Successfully producing an advanced AI chip in 2026 relies not just on logical design; networking fabrics and nanometer-scale fabrication are the true bottlenecks. By deliberately forging a "Triple Alliance," OpenAI has structured a fascinating counter-offensive against Nvidia’s proprietary, closed architecture.
As we know, Nvidia’s massive advantage isn't solely the GPU silicon itself; it’s the NVSwitch networking and Infiniband capabilities (acquired via Mellanox) that allow ten thousand GPUs to operate as a single unified supercomputer. To bypass this monopoly, OpenAI has tapped into the best global alternatives.
- Broadcom’s Foundational Networking Role: Broadcom is unrivaled in building high-end network switches based on open standards (like Advanced Ethernet and PCIe). By leveraging Broadcom’s IP and deep expertise in SerDes (high-speed communication serializers), OpenAI completely sidesteps the need for Nvidia’s closed NVLink solutions. This means Titan chips can scale across racks using cheaper, more standardized protocols, fostering a more open ecosystem rather than being locked into Nvidia’s platform.
- TSMC’s Undisputed Manufacturing Might (3nm Node): Designing the best architecture in the world means nothing without a foundry that can print it with maximum yield rates. Securing immense production capacity on TSMC’s advanced 3-nanometer line (N3E) for Titan signifies OpenAI's endless funding and commitment. Utilizing this cutting-edge lithography ensures OpenAI's custom silicon can stand shoulder-to-shoulder with the thermal stability and transistor density of the industry's finest products.
- Economic Shockwaves to Cloud Providers: This triple alliance exerts immense pressure on Cloud Service Providers (CSPs). When OpenAI develops its own hardware, it reduces its reliance on renting exorbitantly priced compute infrastructure from AWS or Azure (despite the deep Microsoft partnership), positioning itself to eventually become an AI infrastructure provider in the long run.
System Architect (Network Level) Insight:
The decision to select Broadcom for the interconnect layer is an engineering masterstroke. In colossal AI compute clusters, the bottleneck is rarely raw calculation speed; it's the challenge of shuttling trillions of data parameters between chips (the Memory Wall Protocol). Broadcom, with its Tomahawk technology and next-gen switches, provides an interconnect stack that allows OpenAI to link thousands of Titans with minimal traffic congestion. This open-standards architecture stands in direct defiance to the locked-in world of Nvidia servers.
4. Market Fallout from Titan's Emergence: Is Nvidia's Crown Trembling?
OpenAI’s silent and accelerated sprint toward deploying Titan chips in the second half of 2026 sends glaring warning signals to the stock market and to Nvidia’s 100% dominance. While Nvidia is currently surfing on waves of trillion-dollar profits, this development signifies the crystallization of a massive new trend in Silicon Valley: "The Return to Custom Silicon by Cloud and Software Titans."
This trend was previously pioneered by Google with its TPUs (Tensor Processing Units) and Amazon with its Trainium and Inferentia chips. But OpenAI is a fundamentally different beast. They are the creators of the world's most popular and heavily utilized AI models. When the builder of the flagship software decides to migrate from general-purpose hardware to proprietary silicon, the domino effect disrupts the entire global supply chain.
- Nvidia is Safe Short-Term, but Long-Term... : Nvidia’s revenue in 2026 and 2027 will likely remain astronomical due to the insatiable market thirst for "Training" ever-larger foundational models (like 6th-generation language models). But as previously established, the "Inference" market is what ultimately constitutes the primary, sustainable cloud revenue volume. As OpenAI’s inference workloads migrate away from Nvidia-powered servers, a substantial chunk of Nvidia's future inference sales is directly threatened. This is a klaxon alarm that Jensen Huang hears very clearly.
- The Explosive Growth of Broadcom and Marvell: Companies like Broadcom and Marvell Technology, who operate as Custom Silicon Designers and networking specialists, are the biggest winners of this new trend. Broadcom's massive stock surge following the leaked $10 billion contract with OpenAI makes total sense. They have become the new arms dealers of the AI wars.
- A Grim Forecast for AI Hardware Startups: OpenAI’s unilateral move is abysmal news for hundreds of AI chip startups (such as Cerebras or Groq). If the industry titans (Microsoft, Google, Meta, and now OpenAI) are all developing their own powerful internal silicon, the market of independent customers for these startups shrinks violently. Competing against hyper-wealthy corporations that construct silicon exactly molded to their proprietary software models will become practically impossible for smaller players.
Strategic Winner/Loser Analysis:
Absolute Winners: Taiwan’s semiconductor manufacturing ecosystem (TSMC as the exclusive producer), Broadcom (establishing itself as the premier corporate designer partner), and OpenAI itself (vastly improving its gross margins).
Relative Losers: Nvidia (losing the inference segment of its most critical customer) and independent hardware startups dreaming of selling breakthrough tech to the likes of OpenAI.

5. A Preview of the Future: Titan 2 and the Silicon Warfare Roadmap to 2029
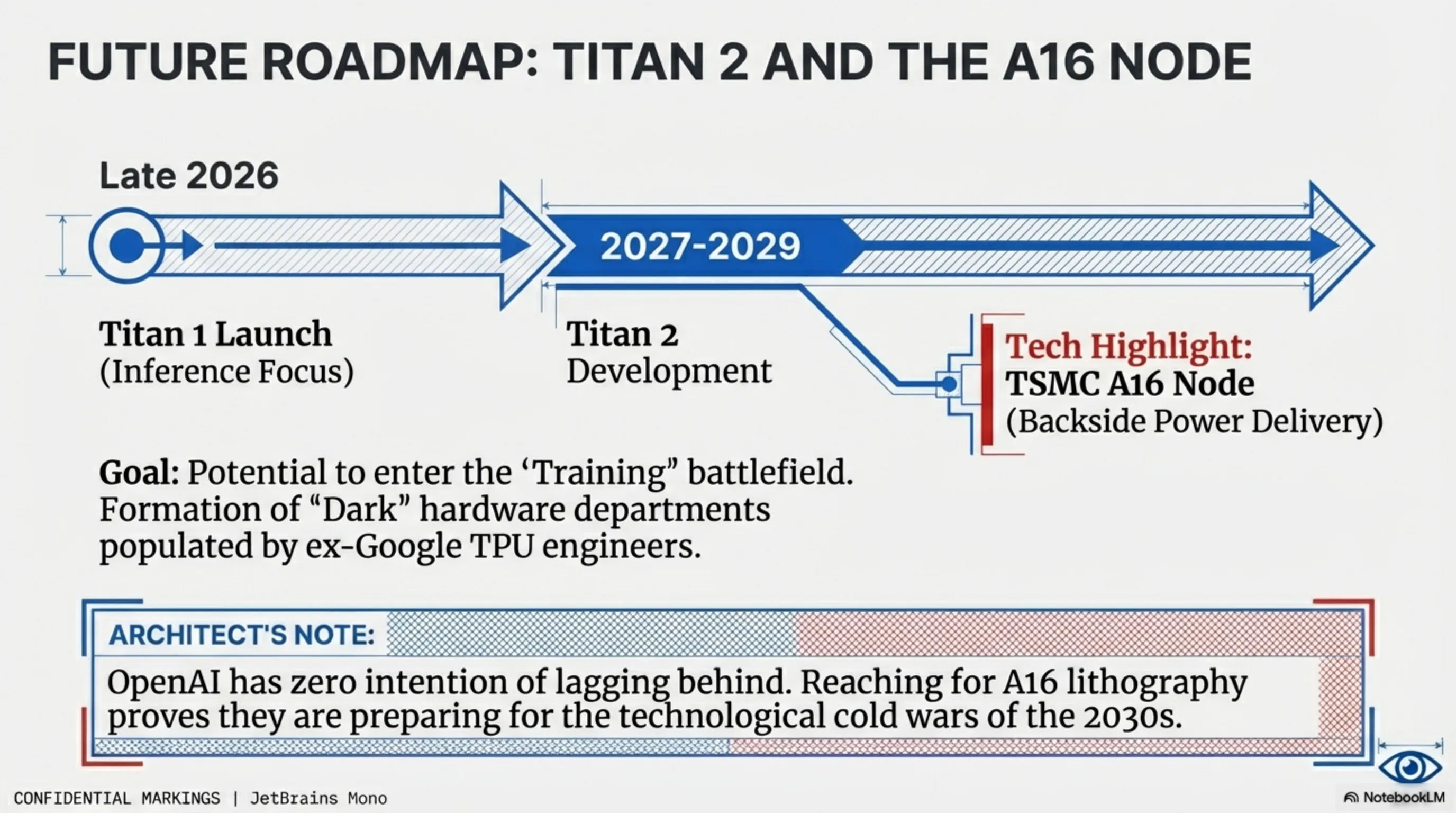
Perhaps the most shocking revelation from the leaked reports is that OpenAI's mission does not end with the first Titan chip. Documents indicate that development of the next generation, the Titan 2 chip, is already underway, slated for initial rollout in late 2026 and massive scaling by 2027. OpenAI's hardware roadmap through 2029 has been laid out with surgical precision, hinting at an even more audacious strategy to breach beyond the boundaries of inference.
The Titan 2 architecture is reportedly targeting TSMC’s ultra-advanced A16 node. The hyped and revolutionary A16 process, which utilizes Backside Power Delivery networks and Nanosheet transistors, allows for incredible frequency scaling and severe reductions in thermal loss. This choice proves OpenAI has zero intention of lagging behind hardcore hardware giants in circuit engineering.
- The Potential Push into the "Training" Battlefield: While the first Titan chip is a perfectly logical move for inference, the more advanced Titan 2 architecture may pack capabilities robust enough to "Train" smaller, highly specialized models. Although fully displacing Nvidia’s training behemoths is daunting, reaching for A16 lithography proves OpenAI is preparing a larger arsenal for the technological cold wars of the 2030s.
- The Formation of "Dark" Hardware Departments: Reports confirm that OpenAI has aggressively headhunted numerous top-tier designers and senior architects formerly of Google (the original TPU team). This brain-drain to a "software" company seemed confusing initially, but the strategy is now crystal clear. The creator of ChatGPT is quietly building hyper-elite hardware architecture divisions behind closed doors.
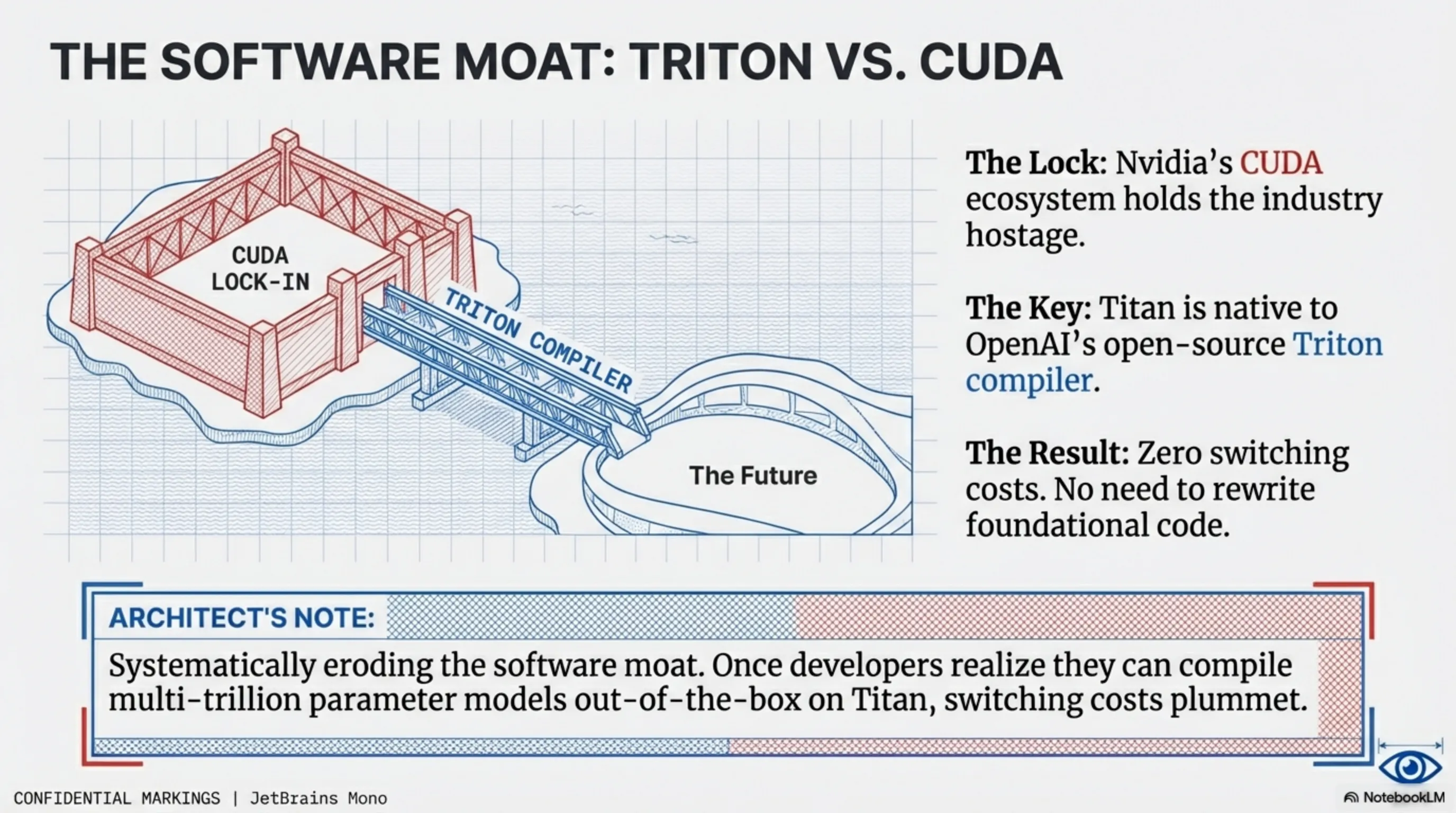
- Software Ecosystem Emancipation (Triton vs. CUDA): One of the most fiercely guarded strategic secrets of the Titan project is its deep, native integration with open-source compiler ecosystems, primarily OpenAI's own Triton project. Currently, the entire AI hardware industry is practically held hostage by Nvidia's proprietary CUDA programming model, making it notoriously difficult and financially risky for AI researchers and developers to migrate their highly complex workloads to alternative hardware platforms. By designing the Titan XPU specifically from the ground up to operate natively, flawlessly, and efficiently with Triton, OpenAI is systematically and aggressively eroding the formidable software moat that Nvidia has spent over a decade building. Once developers realize they can compile their massively parallel, multi-trillion parameter models out-of-the-box on Titan architecture without agonizing over rewriting their entire foundational CUDA codebase, the switching costs will immediately plummet to near zero. This software liberation is just as crucial as the silicon itself.
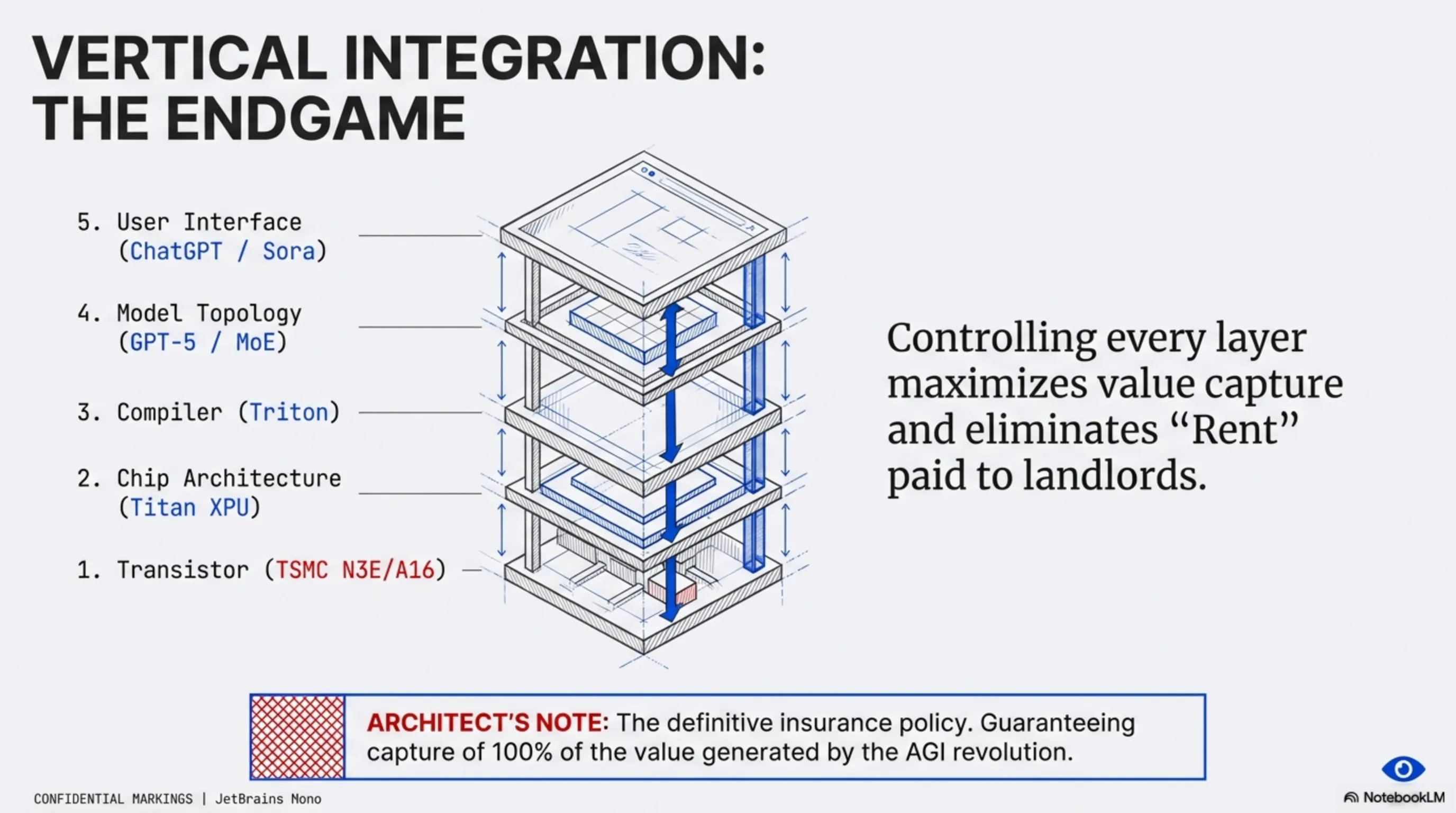
- Absolute Total Vertical Integration: The ultimate, uncompromising endgame is constructing a perfectly, mathematically optimized technological stack—from the individual base transistor layer printed by TSMC, up through the mid-level compiler environments, passing directly into the hyper-complex neural network architectures themselves (such as the MoE or Mixture of Experts topologies heavily favored by modern iterations of GPT and Sora), and finally terminating at the sleek, consumer-facing user interfaces of ChatGPT and related enterprise API endpoints. Controlling every single microscopic layer of this vast technological stack represents the absolute pinnacle of corporate product mastery. It is the definitive insurance policy that guarantees OpenAI will capture 100 percent of the immense financial value generated by the fast-approaching artificial general intelligence (AGI) revolution, ensuring they never have to pay exorbitant rent to any external hardware landlord or silicon monopoly ever again.
System Architect's Futurist Interpretation:
OpenAI’s silicon roadmap clearly demonstrates that we have moved past the "AI Search and Discovery" phase and entered the phase of "Industrialization and Infrastructure Cold War." When the game elevates to the level of placing tens of billions of dollars in bespoke hardware orders with TSMC foundries, the conversation is no longer about a simple chatbot; it is about building the new digital nervous system for the planet. And with the Titan chips, OpenAI has decided not to surrender control of this nervous system to anyone else.

📸 گالری تصاویر


[ Verdict // System Architect Final Ruling ]
OpenAI’s "Project Titan" evaluates as far more than just a new semiconductor; it is a declaration of independence from the most powerful AI company on Earth. By strategically focusing on the Inference layer and forging a historic alliance with Broadcom and TSMC, OpenAI has bypassed Nvidia’s pricing monopoly and compute bottleneck in the smartest way mathematically possible. This move, poised to catastrophically slash Operational Expenditures (OPEX), not only signifies the maturation of AI into heavy-infrastructure industry but also rings a deafening alarm bell for hardware monopolists: In the AGI economy, the ultimate king is the one who exercises absolute, simultaneous control over both the bare metal hardware and the neural brains. The silicon wars of the new decade have officially commenced.