
تاریخچه کامل AI از ۱۹۵۰ تا ۲۰۲۶: تست تورینگ، کنفرانس دارتموث، دو زمستان AI، سیستمهای خبره، Deep Learning، AlexNet، GPT و عصر ChatGPT.
کالبدشکافیِ ۷۶ سال تکاملِ عصبی: از تستِ تورینگ تا ChatGPT
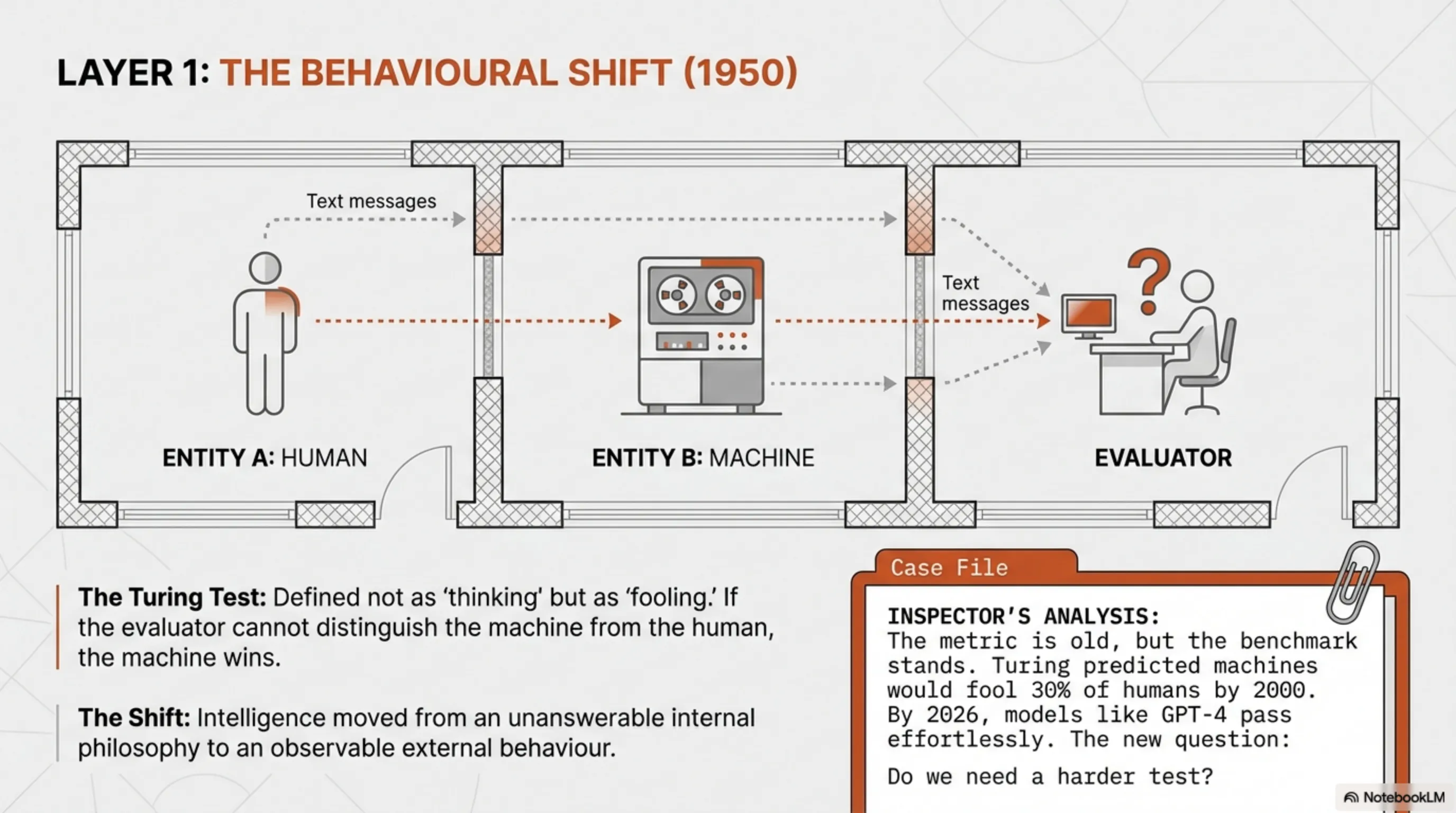
۱۹۵۰. آلن تورینگ، ریاضیدانِ بریتانیایی که رمزهایِ Enigma نازیها رو شکست، یک سؤالِ خطرناک پرسید: "آیا ماشینها میتونن فکر کنن؟" این فقط کنجکاویِ علمی نبود - این یک چالشِ مستقیم به خودِ تعریفِ هوشِ انسانی بود. تورینگ میدونست این سؤالِ فلسفی جوابی نداره، پس یک تستِ عملی طراحی کرد: اگه یک ماشین بتونه توی مکالمه یک انسان رو فریب بده، پس "باهوشه".
امروز، ۷۶ سال بعد، داریم با سیستمهایی کار میکنیم که نهتنها تستِ تورینگ رو پاس کردن، بلکه دارن مرزهایِ جدیدی رو میشکنن که خودِ تورینگ هم تصورشون رو نمیکرد. ChatGPT، GPT-4، Claude، Gemini - اینها دیگه فقط ماشینهایِ پاسخدهنده نیستن. اینها سیستمهایِ استدلالی هستن که ساختارِ تفکرِ انسانی رو شبیهسازی میکنن.
اما چطوری به اینجا رسیدیم؟ این گزارش یک کالبدشکافیِ کاملِ ۷۶ سال تکاملِ عصبیِ ماشینهاست - از اولین الگوریتمهایِ ساده تا شبکههایِ عصبیِ چندمیلیاردپارامتری که الان داریم. این داستان پُره از شکستهایِ فاجعهبار، زمستونهایِ یخزده، و انفجارهایِ ناگهانی که همهچیز رو عوض کردن.
لایه ۱: تستِ تورینگ - اولین پروتکلِ تشخیصِ هوش (۱۹۵۰)
تورینگ یک مشکلِ اساسی داشت: چطوری میشه هوش رو اندازه گرفت؟ فلسفه جوابی نداشت، پس یک معیارِ رفتاری طراحی کرد. تستِ تورینگ ساده بود: یک انسان از پشتِ پرده با دو طرف چت میکنه - یکی انسان، یکی ماشین. اگه نتونه تشخیص بده کدوم ماشینه، ماشین برندهست.
این تست انقلابی بود چون برای اولین بار، هوش رو از "چیزی که توی مغز اتفاق میافته" به "چیزی که از بیرون قابلِ مشاهدهست" تبدیل کرد. دیگه مهم نبود ماشین "واقعاً" فکر میکنه یا نه - مهم این بود که میتونه مثلِ یک موجودِ باهوش رفتار کنه.
📊 آنالیزِ بازرس: چرا تستِ تورینگ هنوز مهمه؟
تستِ تورینگ ۷۶ سالشه، اما هنوز یکی از بهترین معیارهایِ ارزیابیِ AI هست. چرا؟ چون روی رفتار تمرکز داره، نه معماریِ داخلی. GPT-4 و Claude الان راحت این تست رو پاس میکنن، اما سؤالِ جدید اینه: باید یک بنچمارکِ سختتر داشته باشیم؟
تورینگ پیشبینی کرد تا سال ۲۰۰۰، ماشینها میتونن ۳۰٪ از انسانها رو توی یک مکالمهی ۵ دقیقهای فریب بدن. امروز، توی ۲۰۲۶، خیلی از این عدد جلوتر رفتیم. ChatGPT میتونه ساعتها باهات حرف بزنه و شاید حتی متوجه نشی داری با یک ماشین حرف میزنی.

لایه ۲: کنفرانسِ دارتموث - تولدِ رسمیِ AI (۱۹۵۶)
تابستونِ ۱۹۵۶، دانشگاهِ دارتموث. جان مککارتی، ماروین مینسکی، کلود شانون، و ناتانیل روچستر - چهار دانشمندِ جوون که باور داشتن میتونن ماشینهایی بسازن که مثلِ انسان فکر کنن. اونا برای اولین بار اصطلاحِ "هوشِ مصنوعی" رو ساختن و یک هدفِ بلندپروازانه گذاشتن: ساختنِ ماشینهایی که میتونن یاد بگیرن، استدلال کنن، و مسئله حل کنن.
خوشبینیشون غیرواقعی بود. فکر میکردن توی یک تابستون میتونن پیشرفتِ بزرگی بکنن. اما همون شور و اشتیاق باعث تولدِ یک رشتهی علمیِ کاملاً جدید شد. اونا روی مسائلی مثل پردازشِ زبانِ طبیعی، شبکههایِ عصبی، و حلِ مسئله کار کردن - همون چیزهایی که ۷۰ سال بعد هنوز داریم باهاشون دست و پنجه نرم میکنیم.
اما یک چیز رو نمیدونستن: این مسیر چقدر طولانی و پُر از شکسته.
لایه ۳: عصرِ طلایی - خوشبینیِ نامحدود (۱۹۵۶-۱۹۷۴)
بعد از دارتموث، یک عصرِ طلایی شروع شد. همه فکر میکردن توی ۱۰-۲۰ سال، ماشینهایِ باهوشِ مثلِ انسان خواهیم داشت. دولتها بودجههایِ کلان سرمایهگذاری کردن، دانشگاهها آزمایشگاههایِ AI راه انداختن، و رسانهها از آیندهای حرف میزدن که روباتها همهکار میکنن.
توی این دوره، چندتا برنامه ساخته شدن که واقعاً برای اون زمون انقلابی بودن:
ELIZA (۱۹۶۶) - اولین چتباتِ تاریخ که میتونست مثلِ یک رواندرمانگر حرف بزنه. ELIZA از ترفندهایِ ساده برای چیدنِ دوبارهی کلمات و پرسیدنِ سؤال استفاده میکرد. خیلیها باهاش حرف زدن و فکر کردن واقعاً داره گوش میده! این اولین نمونهی "توهمِ هوش" بود - وقتی انسانها به ماشینها هوش نسبت میدن حتی اگه نداشته باشن.
SHRDLU (۱۹۶۸-۱۹۷۰) - برنامهای که میتونست دستورهایِ زبانِ طبیعی رو بفهمه و با مکعبهایِ رنگی توی یک دنیایِ مجازی کار کنه. میتونستی بهش بگی "مکعبِ قرمز رو بذار رویِ مکعبِ آبی" و این کار رو میکرد. این اولین سیستمی بود که میتونست زبانِ انسانی رو به عمل تبدیل کنه.
Shakey the Robot (۱۹۶۶-۱۹۷۲) - اولین روباتِ متحرکی که میتونست برنامهریزی کنه و تصمیم بگیره. اسمش از این بود که وقتی حرکت میکرد میلرزید! Shakey میتونست توی یک اتاق حرکت کنه، موانع رو شناسایی کنه، و مسیر پیدا کنه. این اولین قدم به سمتِ روباتهایِ خودران بود.
⚠️ هشدارِ بازرس: مشکلِ بنیادی
همهی این برنامهها یک مشکلِ مشترک داشتن: فقط توی محیطهایِ خیلی محدود و کنترلشده کار میکردن. ELIZA فقط چندتا الگویِ ساده رو میشناخت. SHRDLU فقط با مکعبهایِ رنگی کار میکرد. Shakey فقط توی یک اتاقِ خالی حرکت میکرد. به محض اینکه میخواستی توی دنیایِ واقعی ازشون استفاده کنی، همهچیز خراب میشد.
لایه ۴: اولین زمستونِ AI - فروپاشیِ رؤیاها (۱۹۷۴-۱۹۸۰)
تا اوایلِ دههی ۷۰، واضح شد که وعدههایِ بزرگِ AI داره محقق نمیشه. کامپیوترها خیلی ضعیف بودن، الگوریتمها محدود بودن، و مهمتر از همه، هنوز نمیفهمیدیم هوش واقعاً چطوری کار میکنه. محققین فکر میکردن میتونن با چندتا قاعدهی منطقی هوش رو شبیهسازی کنن، اما واقعیت خیلی پیچیدهتر بود.
توی ۱۹۷۳، گزارشِ معروفِ "Lighthill Report" توی انگلستان منتشر شد. این گزارش به شدت پیشرفتِ AI رو انتقاد کرد و گفت همهی این تحقیقات به جایی نمیرسه. نتیجه؟ فاجعه. بودجهها قطع شدن، پروژهها تعطیل شدن، و خیلی از محققین مجبور شدن این حوزه رو ترک کنن.
به این دوره "زمستونِ AI" میگن - دورهای که هیچکس حاضر نبود روی AI سرمایهگذاری کنه و همه فکر میکردن یک رؤیایِ غیرممکنه. دانشگاهها بودجهدهی رو متوقف کردن، شرکتها هیچ علاقهای نشون ندادن، و محققین داشتن به حوزههایِ دیگه مهاجرت میکردن.
اما توی این دورهی تاریک، یک چیزی داشت آروم آروم شکل میگرفت که بعداً همهچیز رو عوض کرد: شبکههایِ عصبی. چندتا محققِ لجباز مثلِ جفری هینتون، یان لوکان، و یوشوا بنجیو داشتن روی یک ایده کار میکردن که بقیه رَدش کرده بودن - ایدهی اینکه میشه مغزِ انسان رو با شبکههایِ ریاضی شبیهسازی کرد.

لایه ۵: بازگشتِ امید - سیستمهایِ خبره (۱۹۸۰-۱۹۸۷)
اوایلِ دههی ۸۰، یک نسلِ جدید از سیستمهایِ AI ظاهر شدن: سیستمهایِ خبره. این برنامهها دانشِ متخصصین رو توی یک حوزهی خاص کُدگذاری میکردن و میتونستن مثلِ یک متخصص تصمیم بگیرن. منطق ساده بود: اگه بتونیم دانشِ یک متخصص رو به صورتِ قواعدِ "اگر-آنگاه" بنویسیم، میتونیم یک سیستمِ خبره بسازیم.
MYCIN - یک سیستمِ تشخیصِ پزشکی که میتونست عفونتهایِ خونی رو تشخیص بده و دارو تجویز کنه. توی تستها، دقتش از پزشکانِ عمومی بالاتر بود! MYCIN حدودِ ۶۰۰ قاعده داشت که از متخصصین استخراج شده بود.
XCON - سیستمی که کامپیوترها رو برای شرکتِ DEC پیکربندی میکرد و سالانه میلیونها دلار صرفهجویی میکرد. XCON میتونست بهترین ترکیب رو از هزاران قطعه برای هر سفارش پیدا کنه.
این موفقیتها پول رو دوباره به AI برگردوندن. شرکتها شروع کردن به ساختنِ "ماشینهایِ Lisp" - کامپیوترهایِ تخصصی برای اجرایِ برنامههایِ AI که ۷۰ تا ۱۵۰ هزار دلار قیمت داشتن. ژاپن پروژهی عظیمِ "کامپیوترِ نسلِ پنجم" رو راه انداخت با هدفِ ساختنِ سوپرکامپیوترهایِ باهوش که قرار بود تا ۱۹۹۲ دنیا رو عوض کنن.
اما دوباره، خوشبینی زیادی بود...
لایه ۶: دومین زمستونِ AI - فروپاشیِ سیستمهایِ خبره (۱۹۸۷-۱۹۹۳)
تا اواخرِ دههی ۸۰، واضح شد که سیستمهایِ خبره هم محدودیتهایِ جدی دارن. مشکلاتِ اصلی اینها بودن:
۱. نگهداریِ سخت - هر بار که قواعد عوض میشدن، باید همهچیز رو دستی آپدیت میکردی. یک سیستمِ خبرهی پزشکی ممکن بود هزاران قاعده داشته باشه، و هر بار که یک داروی جدید اضافه میشد، باید صدها قاعده رو دوباره مینوشتی.
۲. مقیاسپذیریِ ضعیف - برای حوزههایِ پیچیده، تعدادِ قواعد به هزاران تا میرسید و سیستم خیلی کُند میشد. محققین فهمیدن نمیشه همهی دانشِ انسانی رو به صورتِ قاعده کُدگذاری کرد.
۳. شکنندگی - اگه یک سؤالِ خارج از دانشِ سیستم میپرسیدی، کاملاً گیج میشد و جوابهایِ مسخره میداد. این سیستمها هیچ "عقلِ سلیمی" نداشتن.
توی ۱۹۸۷، بازارِ ماشینهایِ Lisp فروپاشید. کامپیوترهایِ شخصی ارزونتر و قویتر شده بودن، و دیگه هیچکس حاضر نبود صدها هزار دلار برای یک ماشینِ تخصصی بده. شرکتهایِ سازندهی ماشینهایِ Lisp یکی یکی ورشکست شدن.
پروژهی نسلِ پنجمِ ژاپن هم با شکستِ فاجعهبار مواجه شد. بعد از ۱۰ سال و میلیاردها دلار سرمایهگذاری، نتونستن هیچکدوم از اهدافشون رو محقق کنن. دوباره بودجهها قطع شدن و محققین دلسرد شدن.
اما این بار، یک چیزی فرق داشت. توی پسزمینه، یک انقلابِ آروم داشت شکل میگرفت که همهچیز رو عوض کرد...

لایه ۷: انقلابِ آروم - یادگیریِ ماشین و شبکههایِ عصبی (۱۹۹۰-۲۰۱۰)
توی دههی ۹۰، محققین شروع کردن متفاوت فکر کردن: به جایِ اینکه قواعد رو دستی برنامهنویسی کنیم، چرا به ماشین یاد ندیم که از دیتا یاد بگیره؟ این یک تغییرِ پارادایم بود - از "برنامهنویسیِ صریح" به "یادگیری از دیتا".
چندتا رویدادِ کلیدی این دوره رو تعریف کردن:
۱۹۹۷ - Deep Blue کاسپاروف رو شکست میده - کامپیوترِ IBM برای اولین بار قهرمانِ جهانِ شطرنج رو شکست داد. این یک نقطهی عطف بود - نشون داد ماشینها میتونن توی کارهایِ پیچیده از انسان بهتر عمل کنن. Deep Blue ثانیهای ۲۰۰ میلیون حالت رو بررسی میکرد، در حالی که کاسپاروف فقط ۳-۵ حالت رو آنالیز میکرد. اما قدرتِ محاسباتیِ خام برنده شد.
۱۹۹۸ - MNIST و تشخیصِ دستخط - یان لوکان و تیمش یک شبکهی عصبیِ کانولوشنال (CNN) ساختن که میتونست اعدادِ دستنویس رو با دقتِ ۹۹٪ تشخیص بده. این اولین کاربردِ تجاریِ موفقِ شبکههایِ عصبی بود، و بانکها شروع کردن ازش برای خوندنِ چکها استفاده کنن.
۲۰۰۶ - یادگیریِ عمیق - جفری هینتون و تیمش نشون دادن که میشه شبکههایِ عصبیِ عمیق (با لایههایِ متعدد) رو آموزش داد. این شروعِ انقلابِ Deep Learning بود. قبل از این، همه فکر میکردن شبکههایِ عمیق قابلِ آموزش نیستن چون گرادیانها محو میشن. هینتون این مشکل رو با تکنیکِ "پیشآموزش" حل کرد.
🔧 بینشِ تکنیکی: چرا الان؟
سؤالِ مهم این بود: چرا شبکههایِ عصبی که از دههی ۶۰ وجود داشتن تا ۲۰۰۶ کار نکردن؟ جواب سادست: سه چیز کم بود - دیتا، قدرتِ محاسباتی، و الگوریتمهایِ بهتر. تا اوایلِ دههی ۲۰۰۰، هیچکدوم از اینها رو نداشتیم.
اما هنوز یک چیز کم بود: دیتایِ کافی و قدرتِ محاسباتی. اینترنت داشت رشد میکرد، اما هنوز دیتایِ کافی نداشتیم. GPUها هنوز برای گیمینگ استفاده میشدن، نه برای AI. همهچیز آماده بود، فقط باید صبر میکردیم...
لایه ۸: بیگ بنگ - عصرِ یادگیریِ عمیق (۲۰۱۲-۲۰۲۰)
توی ۲۰۱۲، همهچیز عوض شد. الکس کریژفسکی، دانشجویِ دکترایِ جفری هینتون، یک شبکهی عصبیِ عمیق به اسمِ AlexNet ساخت که رکوردهایِ مسابقهی ImageNet رو شکست. دقتش اونقدر بالا بود که همه شوکه شدن. این لحظهای بود که Deep Learning از تحقیقاتِ آکادمیک به تکنولوژیِ عملی تبدیل شد.
چرا الان؟ سه چیز کنارِ هم قرار گرفتن:
۱. دیتایِ زیاد - اینترنت و شبکههایِ اجتماعی میلیاردها عکس و متن تولید کرده بودن. فقط ImageNet ۱۴ میلیون عکسِ برچسبخورده داشت. این حجمِ دیتا قبلاً وجود نداشت.
۲. GPUها - کارتگرافیکهایی که برای گیمینگ ساخته شده بودن، برای آموزشِ شبکههایِ عصبی عالی بودن. AlexNet روی دوتا NVIDIA GTX 580 آموزش داده شد - کارتهایی که ۵۰۰ دلار قیمت داشتن، نه ۵۰۰ هزار دلار.
۳. الگوریتمهایِ بهتر - تکنیکهایی مثلِ Dropout (برای جلوگیری از overfitting)، ReLU (تابعِ فعالسازیِ سریعتر)، و Batch Normalization آموزش رو راحتتر کردن.
بعد از ۲۰۱۲، یک سیلِ پیشرفت شروع شد:
۲۰۱۴ - GANها - ایان گودفلو شبکههایِ تولیدیِ متخاصم رو معرفی کرد که میتونستن عکسهایِ واقعگرایانه بسازن. ایده ساده بود: دوتا شبکهی عصبی با هم رقابت میکنن - یکی عکسهایِ فیک میسازه، یکی سعی میکنه تشخیص بده فیکن یا واقعی. این رقابت هر دو رو بهتر میکنه.
۲۰۱۶ - AlphaGo - سیستمِ DeepMind قهرمانِ جهانِ بازیِ Go رو شکست داد. این خیلی سختتر از شطرنج بود چون Go حالتهایِ بیشتری داره (۱۰^۱۷۰ حالت در مقابلِ ۱۰^۱۲۰ حالتِ شطرنج). AlphaGo ترکیبی از Deep Learning و Monte Carlo Tree Search بود.
۲۰۱۷ - Transformer - محققینِ گوگل مقالهی "Attention is All You Need" رو منتشر کردن و معماریِ Transformer رو معرفی کردن. این معماری بعداً پایهی GPT، BERT، و همهی مدلهایِ زبانیِ بزرگ شد. Transformer میتونست با مکانیزمِ "توجه" روابطِ بین کلمات رو بهتر یاد بگیره.
۲۰۱۸ - GPT-1 - OpenAI اولین نسخهی GPT رو با ۱۱۷ میلیون پارامتر منتشر کرد. این شروعِ یک انقلاب بود که هنوز ادامه داره.
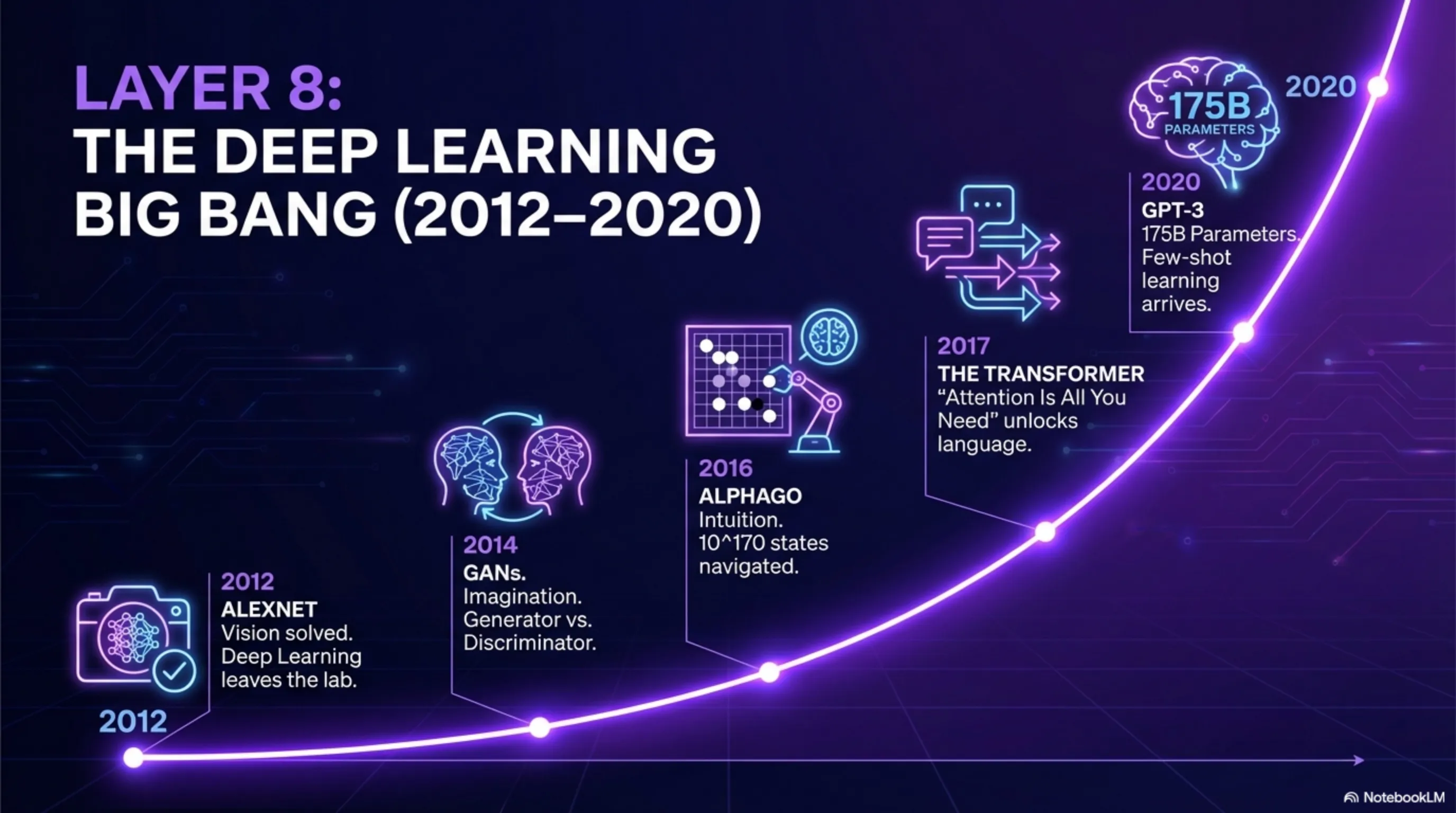
۲۰۲۰ - GPT-3 - OpenAI یک مدل با ۱۷۵ میلیارد پارامتر منتشر کرد که میتونست متنهایِ شبیهِ انسان بنویسه، کُد بنویسه، و حتی استدلال کنه. این اولین باری بود که یک مدلِ زبانی میتونست بدونِ آموزشِ خاص کارهایِ پیچیده انجام بده (few-shot learning).
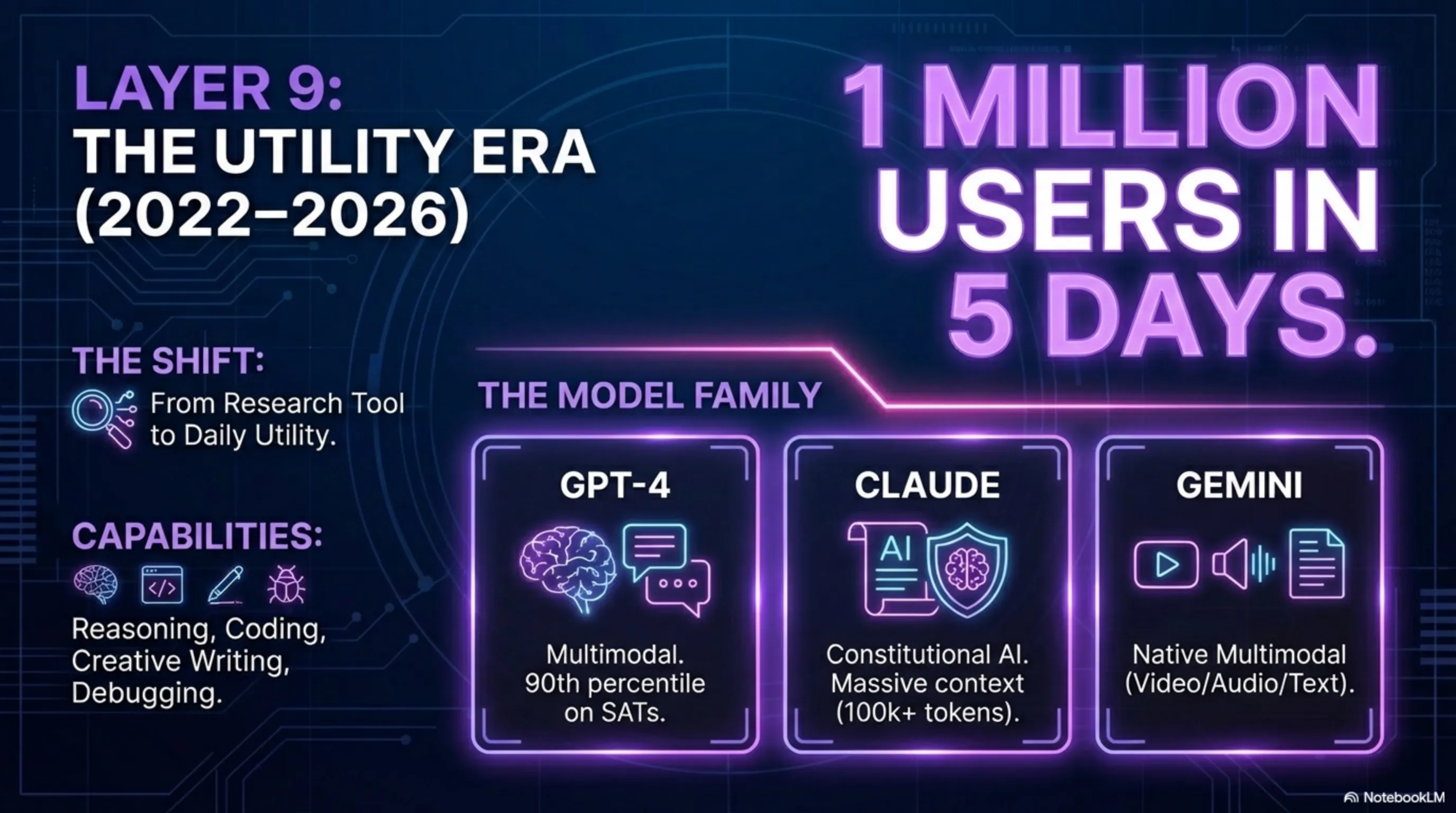
لایه ۹: عصرِ ChatGPT - AI برای همه (۲۰۲۲-۲۰۲۶)
نوامبرِ ۲۰۲۲، OpenAI چتجیپیتی رو منتشر کرد و همهچیز عوض شد. توی ۵ روز، ۱ میلیون کاربر. توی ۲ ماه، ۱۰۰ میلیون کاربر. سریعترین رشد توی تاریخِ تکنولوژی. چرا؟ چون برای اولین بار، یک AIِ قدرتمند به صورتِ رایگان و ساده در دسترسِ همه بود.
ChatGPT فقط یک چتبات نبود. یک سیستمِ استدلالی بود که میتونست: کُد بنویسه و دیباگ کنه، مقاله و محتوا تولید کنه، به سؤالاتِ پیچیده جواب بده، زبانها رو ترجمه کنه، ایدههایِ خلاقانه بده، و مثلِ یک معلم توضیح بده.
بعد از ChatGPT، یک سیلِ مدلهایِ جدید اومدن:
۲۰۲۳ - GPT-4 - یک مدلِ چندوجهی که میتونست عکسها رو هم ببینه. GPT-4 توی تستهایِ استاندارد مثلِ SAT و GRE بالاتر از ۹۰٪ انسانها امتیاز گرفت.
۲۰۲۳ - Claude - Anthropic یک مدل ساخت که روی "AIِ قانوناساسی" تمرکز داشت - یعنی یک AIِ اخلاقیتر و امنتر. Claude میتونست متنهایِ خیلی طولانی رو پردازش کنه (تا ۱۰۰ هزار توکن).
۲۰۲۴ - Gemini - گوگل یک مدل منتشر کرد که از اول طراحی شده بود چندوجهی باشه. Gemini میتونست همزمان با متن، عکس، صدا، و ویدیو کار کنه.
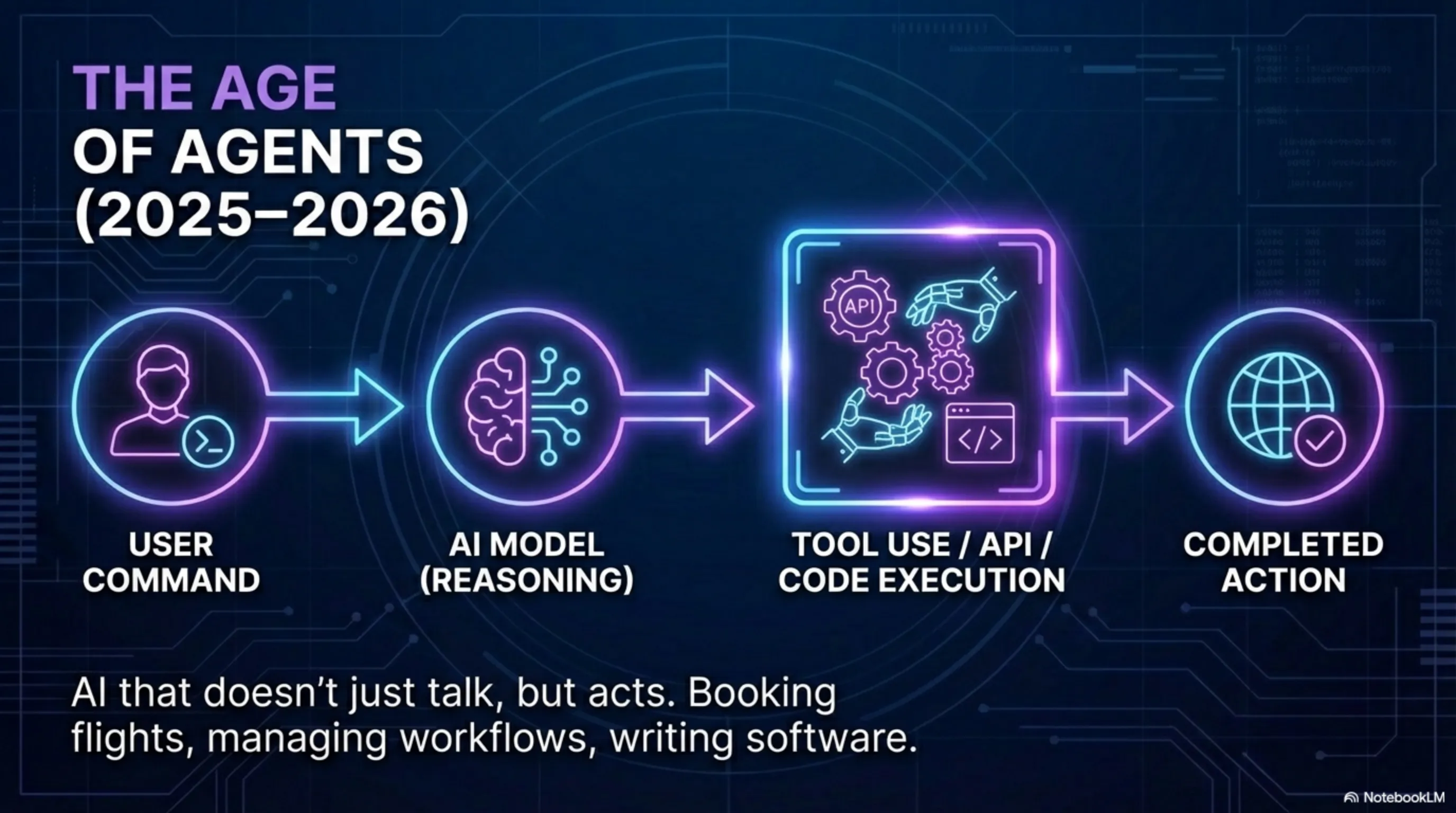
۲۰۲۵-۲۰۲۶ - عصرِ ایجنتها - مدلهایِ جدید دیگه فقط پاسخ نمیدن، بلکه میتونن اقدام کنن. میتونن کُد بنویسن و اجرا کنن، با APIها کار کنن، و حتی با ابزارهایِ دیگه تعامل کنن. این شروعِ عصرِ "ایجنتهایِ AI" هست - سیستمهایی که میتونن به صورتِ خودکار کارها رو انجام بدن.
🚨 آنالیزِ بحرانی: کجا ایستادیم؟
سالِ ۲۰۲۶ هست و داریم با سیستمهایی کار میکنیم که ۷۶ سال پیش غیرممکن به نظر میرسیدن. اما هنوز مشکلاتِ جدی داریم: توهمزایی (تولیدِ اطلاعاتِ غلط)، تعصب (پیشداوریها توی دیتایِ آموزشی)، قابلیتِ تفسیر (دقیقاً نمیدونیم چطوری تصمیم میگیرن)، و ایمنی (چطوری مطمئن بشیم کنترل رو از دست نمیدیم). اینها چالشهایِ بعدی هستن که باید حل بشن.
نتیجهگیری: از تستِ تورینگ تا ایجنتهایِ خودمختار
۷۶ سال طول کشید تا از یک سؤالِ ساده ("آیا ماشینها میتونن فکر کنن؟") به سیستمهایی برسیم که نهتنها فکر میکنن، بلکه میتونن یاد بگیرن، خلق کنن، و حتی استدلال کنن. این مسیر پُر از شکست بود - دوتا زمستونِ AI، پروژههایِ میلیاردی که به جایی نرسیدن، و دههها تحقیق که به بنبست خوردن.
اما چیزی که این داستان رو جالب میکنه، پافشاریِ محققینی مثلِ جفری هینتون، یان لوکان، و یوشوا بنجیو هست که حتی توی سختترین زمانها، به شبکههایِ عصبی ایمان داشتن. اونا میدونستن مغزِ انسان با نورونها کار میکنه، پس چرا نشه با ریاضیات شبیهسازیش کرد؟
الان داریم شاهدِ یک تحولِ بنیادی هستیم. AI دیگه فقط یک ابزارِ تحقیقاتی نیست - تبدیل شده به یک تکنولوژیِ عمومی که داره همهچیز رو عوض میکنه. از نحوهی کارمون، تا نحوهی یادگیریمون، تا نحوهی تولیدِ محتوا.
سؤال دیگه "آیا ماشینها میتونن فکر کنن؟" نیست. سؤال شده: "چطوری میتونیم با ماشینهایِ متفکر زندگی کنیم؟"
🎯 خلاصهی کالبدشکافی
۱۹۵۰-۱۹۵۶: تستِ تورینگ و تولدِ AI - رؤیایِ ماشینهایِ متفکر
۱۹۵۶-۱۹۷۴: عصرِ طلایی - خوشبینیِ نامحدود و برنامههایِ اولیه
۱۹۷۴-۱۹۸۰: زمستونِ اول - فروپاشیِ رؤیاها و قطعِ بودجهها
۱۹۸۰-۱۹۸۷: سیستمهایِ خبره - بازگشتِ امید با قواعدِ دستی
۱۹۸۷-۱۹۹۳: زمستونِ دوم - شکستِ سیستمهایِ خبره
۱۹۹۰-۲۰۱۰: انقلابِ آروم - یادگیریِ ماشین و شبکههایِ عصبی
۲۰۱۲-۲۰۲۰: بیگ بنگ - یادگیریِ عمیق و AlexNet
۲۰۲۲-۲۰۲۶: عصرِ ChatGPT - AI برای همه و ایجنتهایِ خودمختار
💼 یادداشتِ بازرس: تجهیزاتِ پیشنهادی برای عصرِ AI
بعد از کالبدشکافیِ ۷۶ سال تکاملِ AI، یک چیز واضحه: این تکنولوژی برنمیگرده. اگه میخوای توی این عصرِ جدید زنده بمونی، به سختافزارِ قدرتمند نیاز داری. اینها تجهیزاتی هستن که من شخصاً پیشنهاد میکنم:
🖥️ سیستمهایِ گیمینگِ قدرتمند
برای اجرایِ مدلهایِ محلیِ AI (مثلِ LLaMA یا Stable Diffusion)، به یک GPUِ قدرتمند نیاز داری. کارتگرافیکهایِ NVIDIA RTX 4080 یا 4090 بهترین گزینهها هستن. همون کارتهایی که برای گیمینگ استفاده میشن، برای AI عالی هستن.
💻 لپتاپهایِ حرفهای
اگه میخوای همهجا با AI کار کنی، به یک لپتاپِ قدرتمند نیاز داری. لپتاپهایِ گیمینگ با RTX 4070 یا بالاتر میتونن مدلهایِ کوچکتر رو اجرا کنن. حداقل ۳۲ گیگ RAM پیشنهاد میشه.
⚡ حافظه و استوریج
مدلهایِ AI بزرگن. یک SSDِ NVMe سریع (حداقل ۱ ترابایت) ضروریه. برای کار با دیتاستهایِ بزرگ، ۶۴ گیگ RAM ایدهآله.
🎮 همهی این تجهیزات رو میتونی از فروشگاهِ تکینگیم تهیه کنی - با گارانتیِ معتبر و پشتیبانیِ فنی.