
تاريخ كامل للذكاء الاصطناعي من 1950 إلى 2026: اختبار تورينغ، مؤتمر دارتموث، شتاءان للذكاء الاصطناعي، الأنظمة الخبيرة، التعلم العميق، AlexNet، GPT وعصر ChatGPT.
تشريح 76 عاماً من التطور العصبي: من اختبار تورينغ إلى ChatGPT
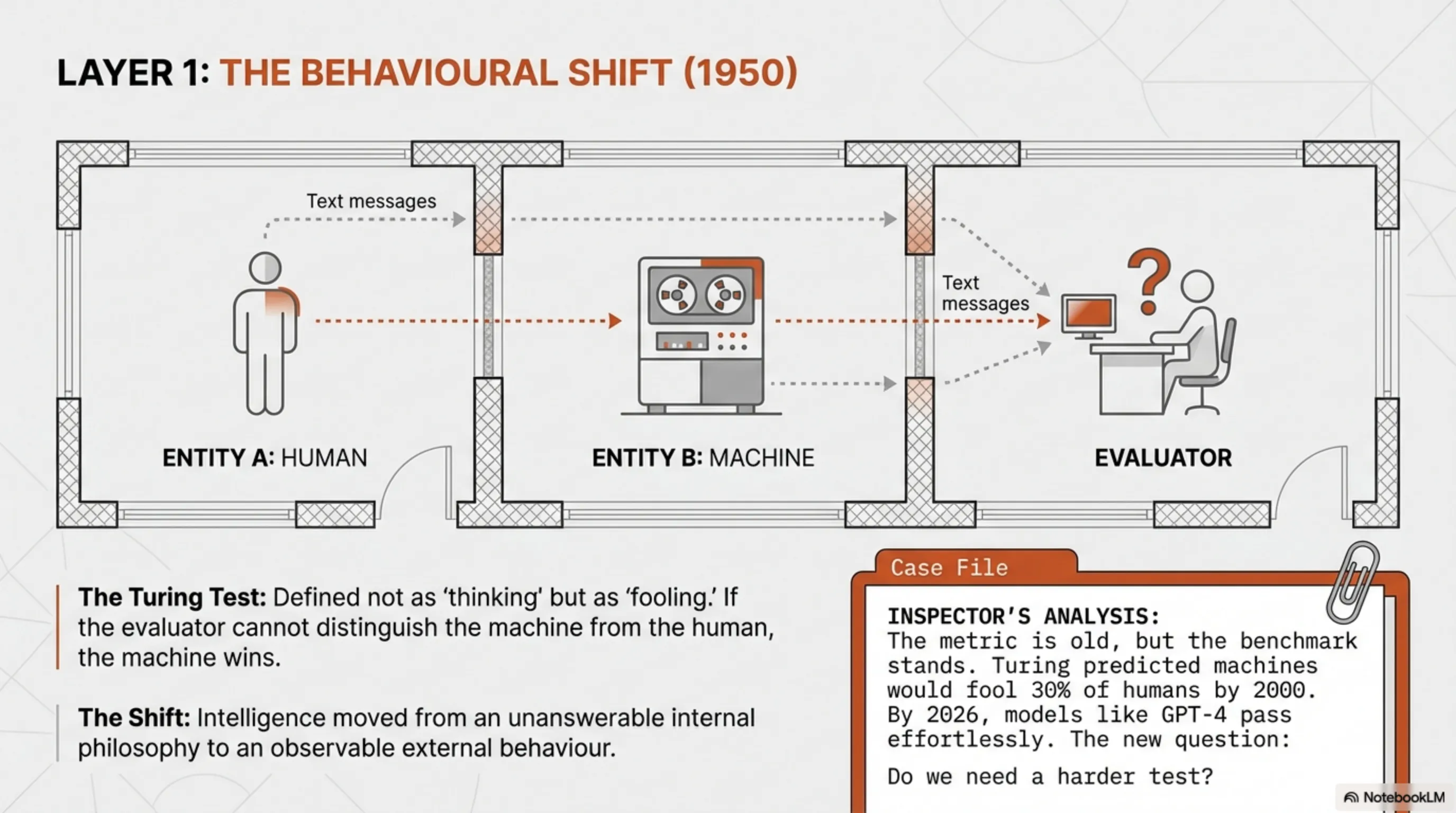
عام 1950. آلان تورينغ، عالم الرياضيات البريطاني الذي فكّ شفرات Enigma النازية، طرح سؤالاً خطيراً: "هل يمكن للآلات أن تفكر؟" لم يكن هذا السؤال مجرد فضول علمي، بل كان تحدياً مباشراً لتعريف الذكاء البشري نفسه. كان تورينغ يعلم أن هذا السؤال الفلسفي لا إجابة له، لذا صمم اختباراً عملياً: إذا استطاعت آلة خداع إنسان في محادثة، فهي "ذكية".
اليوم، بعد 76 عاماً، نعمل مع أنظمة لم تجتز اختبار تورينغ فحسب، بل تكسر حدوداً جديدة لم يتخيلها تورينغ نفسه. ChatGPT وGPT-4 وClaude وGemini - لم تعد هذه مجرد آلات استجابة. إنها أنظمة استدلالية تحاكي بنية التفكير البشري.
لكن كيف وصلنا إلى هنا؟ هذا التقرير تشريح كامل لـ76 عاماً من التطور العصبي للآلات - من الخوارزميات البسيطة الأولى إلى الشبكات العصبية متعددة المليارات من المعاملات التي نمتلكها الآن. هذه قصة مليئة بالإخفاقات الكارثية، والشتاءات المتجمدة، والانفجارات المفاجئة التي غيرت كل شيء.
الطبقة 1: اختبار تورينغ - أول بروتوكول لكشف الذكاء (1950)
كان لدى تورينغ مشكلة أساسية: كيف يمكن قياس الذكاء؟ لم يكن للفلسفة إجابة، لذا صمم معياراً سلوكياً. كان اختبار تورينغ بسيطاً: يتحدث إنسان من وراء ستار مع طرفين - أحدهما إنسان والآخر آلة. إذا لم يستطع التمييز أيهما الآلة، فالآلة هي الفائزة.
كان هذا الاختبار ثورياً لأنه للمرة الأولى حوّل الذكاء من "شيء يحدث داخل الدماغ" إلى "شيء يمكن ملاحظته من الخارج". لم يعد مهماً ما إذا كانت الآلة "تفكر حقاً" - المهم هو ما إذا كانت تستطيع التصرف ككائن ذكي.
📊 تحليل المفتش: لماذا لا يزال اختبار تورينغ مهماً؟
عمر اختبار تورينغ 76 عاماً، لكنه لا يزال أحد أفضل معايير تقييم الذكاء الاصطناعي. لماذا؟ لأنه يركز على السلوك، وليس البنية الداخلية. GPT-4 وClaude يجتازان هذا الاختبار بسهولة الآن، لكن السؤال الجديد هو: هل يجب أن يكون لدينا معيار أصعب؟
توقع تورينغ أنه بحلول عام 2000، ستتمكن الآلات من خداع 30٪ من البشر في محادثة مدتها 5 دقائق. اليوم، في عام 2026، تجاوزنا هذا الرقم بكثير. يمكن لـChatGPT التحدث معك لساعات وقد لا تدرك حتى أنك تتحدث مع آلة.

الطبقة 2: مؤتمر دارتموث - الميلاد الرسمي للذكاء الاصطناعي (1956)
صيف 1956، جامعة دارتموث. جون مكارثي ومارفن مينسكي وكلود شانون وناثانيال روتشستر - أربعة علماء شباب آمنوا بأنهم يستطيعون بناء آلات تفكر مثل البشر. استخدموا مصطلح "الذكاء الاصطناعي" لأول مرة وحددوا هدفاً طموحاً: بناء آلات يمكنها التعلم والاستدلال وحل المشكلات.
كان تفاؤلهم غير واقعي. ظنوا أنهم يستطيعون إحراز تقدم كبير في صيف واحد. لكن تلك الحماسة أدت إلى ولادة مجال علمي جديد تماماً. عملوا على مشاكل مثل معالجة اللغة الطبيعية والشبكات العصبية وحل المشكلات - نفس الأشياء التي لا نزال نتعامل معها بعد 70 عاماً.
لكنهم لم يعرفوا شيئاً واحداً: كم سيكون هذا الطريق طويلاً ومليئاً بالفشل.
الطبقة 3: العصر الذهبي - التفاؤل اللامحدود (1956-1974)
بعد دارتموث، بدأ عصر ذهبي. اعتقد الجميع أنه في غضون 10-20 عاماً، سيكون لدينا آلات ذكية مثل البشر. استثمرت الحكومات أموالاً ضخمة، وأطلقت الجامعات مختبرات للذكاء الاصطناعي، وتحدثت وسائل الإعلام عن مستقبل تقوم فيه الروبوتات بكل شيء.
خلال هذه الحقبة، تم بناء عدة برامج كانت ثورية حقاً لذلك الوقت:
ELIZA (1966) - أول روبوت محادثة في التاريخ يمكنه التحدث مثل معالج نفسي. استخدمت ELIZA حيلاً بسيطة لإعادة ترتيب الكلمات وطرح الأسئلة. إذا قلت "أنا حزين"، كانت تسأل "لماذا أنت حزين؟" تحدث الكثيرون معها واعتقدوا أنها تستمع حقاً! كان هذا أول مثال على "وهم الذكاء" - عندما ينسب البشر الذكاء للآلات حتى لو لم تكن تمتلكه.
SHRDLU (1968-1970) - برنامج يمكنه فهم أوامر اللغة الطبيعية والعمل مع كتل ملونة في عالم افتراضي. يمكنك أن تقول له "ضع الكتلة الحمراء على الكتلة الزرقاء" وسيفعل ذلك. كان هذا أول نظام يمكنه تحويل اللغة البشرية إلى فعل.
Shakey the Robot (1966-1972) - أول روبوت متحرك يمكنه التخطيط واتخاذ القرارات. سُمي بذلك لأنه كان يهتز عند الحركة! كان Shakey يستطيع التحرك في غرفة، وتحديد العوائق، وإيجاد المسارات. كانت هذه الخطوة الأولى نحو الروبوتات ذاتية القيادة.
⚠️ تحذير المفتش: المشكلة الأساسية
كانت لجميع هذه البرامج مشكلة مشتركة: كانت تعمل فقط في بيئات محدودة ومضبوطة للغاية. كانت ELIZA تستطيع فقط التعرف على بضعة أنماط بسيطة. كان SHRDLU يعمل فقط مع كتل ملونة. كان Shakey يتحرك فقط في غرفة فارغة. بمجرد محاولة استخدامها في العالم الحقيقي، كان كل شيء ينهار.
الطبقة 4: شتاء الذكاء الاصطناعي الأول - انهيار الأحلام (1974-1980)
بحلول أوائل السبعينيات، أصبح واضحاً أن الوعود الكبيرة للذكاء الاصطناعي لن تتحقق. كانت أجهزة الكمبيوتر ضعيفة جداً، والخوارزميات محدودة، والأهم من ذلك، لم نكن نفهم بعد كيف يعمل الذكاء حقاً. اعتقد الباحثون أنهم يستطيعون محاكاة الذكاء ببضع قواعد منطقية، لكن الواقع كان أكثر تعقيداً بكثير.
في عام 1973، نُشر تقرير "Lighthill Report" الشهير في إنجلترا. انتقد هذا التقرير بشدة تقدم الذكاء الاصطناعي وقال إن كل هذا البحث لن يؤدي إلى أي مكان. النتيجة؟ كارثة. تم قطع الميزانيات، وأُغلقت المشاريع، واضطر العديد من الباحثين إلى ترك المجال.
تُسمى هذه الفترة "شتاء الذكاء الاصطناعي" - فترة لم يكن فيها أحد مستعداً للاستثمار في الذكاء الاصطناعي واعتقد الجميع أنه حلم مستحيل. توقفت الجامعات عن التمويل، ولم تُظهر الشركات أي اهتمام، وكان الباحثون يهاجرون إلى مجالات أخرى.
لكن خلال هذه الفترة المظلمة، كان شيء ما يتشكل ببطء وسيغير كل شيء لاحقاً: الشبكات العصبية. كان عدد قليل من الباحثين العنيدين مثل جيفري هينتون ويان لوكون ويوشوا بنجيو يعملون على فكرة رفضها الجميع - فكرة أنه يمكن محاكاة الدماغ البشري بشبكات رياضية.

الطبقة 5: عودة الأمل - الأنظمة الخبيرة (1980-1987)
في أوائل الثمانينيات، ظهر جيل جديد من أنظمة الذكاء الاصطناعي: الأنظمة الخبيرة. كانت هذه البرامج تشفّر معرفة الخبراء في مجال معين ويمكنها اتخاذ قرارات مثل المتخصص. كان المنطق بسيطاً: إذا استطعنا كتابة معرفة خبير كقواعد "إذا-ثم"، يمكننا بناء نظام خبير.
MYCIN - نظام تشخيص طبي يمكنه تشخيص التهابات الدم ووصف الأدوية. في الاختبارات، كانت دقته أعلى من الأطباء العامين! كان لدى MYCIN حوالي 600 قاعدة مستخرجة من المتخصصين.
XCON - نظام قام بتكوين أجهزة الكمبيوتر لشركة DEC ووفر ملايين الدولارات سنوياً. كان XCON يستطيع إيجاد أفضل مجموعة من آلاف القطع لكل طلب.
أعادت هذه النجاحات الأموال إلى مجال الذكاء الاصطناعي. بدأت الشركات في بناء "آلات Lisp" - أجهزة كمبيوتر مخصصة لتشغيل برامج الذكاء الاصطناعي تكلف من 70 ألف إلى 150 ألف دولار. أطلقت اليابان مشروع "الجيل الخامس من الكمبيوتر" الضخم بهدف بناء حواسيب عملاقة ذكية كان من المفترض أن تغير العالم بحلول عام 1992.
لكن مرة أخرى، كان التفاؤل مفرطاً...
الطبقة 6: شتاء الذكاء الاصطناعي الثاني - انهيار الأنظمة الخبيرة (1987-1993)
بحلول أواخر الثمانينيات، أصبح واضحاً أن الأنظمة الخبيرة لديها أيضاً قيود خطيرة. كانت المشاكل الرئيسية:
1. صعوبة الصيانة - في كل مرة تتغير فيها القواعد، كان عليك تحديث كل شيء يدوياً. قد يكون لنظام خبير طبي آلاف القواعد، وفي كل مرة تُضاف فيها دواء جديد، كان عليك إعادة كتابة مئات القواعد.
2. قابلية التوسع الضعيفة - بالنسبة للمجالات المعقدة، وصل عدد القواعد إلى الآلاف وأصبح النظام بطيئاً جداً. أدرك الباحثون أنه لا يمكن ترميز كل المعرفة البشرية كقواعد.
3. الهشاشة - إذا طرحت سؤالاً خارج معرفة النظام، كان يرتبك تماماً ويعطي إجابات سخيفة. لم يكن لهذه الأنظمة أي "حس سليم".
في عام 1987، انهار سوق آلات Lisp. أصبحت أجهزة الكمبيوتر الشخصية أرخص وأقوى، ولم يعد أحد مستعداً لدفع مئات الآلاف من الدولارات لآلة مخصصة. أفلست شركات آلات Lisp واحدة تلو الأخرى.
واجه مشروع الجيل الخامس الياباني أيضاً فشلاً كارثياً. بعد 10 سنوات ومليارات الدولارات من الاستثمار، لم يتمكنوا من تحقيق أي من أهدافهم. مرة أخرى، تم قطع الميزانيات وأصيب الباحثون بالإحباط.
لكن هذه المرة، كان هناك شيء مختلف. في الخلفية، كانت ثورة هادئة تتشكل ستغير كل شيء...

الطبقة 7: الثورة الهادئة - التعلم الآلي والشبكات العصبية (1990-2010)
في التسعينيات، بدأ الباحثون التفكير بطريقة مختلفة: بدلاً من برمجة القواعد يدوياً، لماذا لا نعلّم الآلة أن تتعلم من البيانات؟ كان هذا تحولاً في النموذج - من "البرمجة الصريحة" إلى "التعلم من البيانات".
حددت عدة أحداث رئيسية هذه الحقبة:
1997 - Deep Blue يهزم كاسباروف - هزم كمبيوتر IBM بطل العالم في الشطرنج لأول مرة. كانت هذه نقطة تحول - أظهرت أن الآلات يمكنها التفوق على البشر في المهام المعقدة. فحص Deep Blue 200 مليون موضع في الثانية، بينما حلل كاسباروف 3-5 مواضع فقط. لكن القوة الحسابية الخام فازت.
1998 - MNIST والتعرف على خط اليد - بنى يان لوكون وفريقه شبكة عصبية تلافيفية (CNN) يمكنها التعرف على الأرقام المكتوبة بخط اليد بدقة 99٪. كان هذا أول تطبيق تجاري ناجح للشبكات العصبية، وبدأت البنوك في استخدامه لقراءة الشيكات.
2006 - التعلم العميق - أظهر جيفري هينتون وفريقه أنه يمكن تدريب الشبكات العصبية العميقة (ذات الطبقات المتعددة). كانت هذه بداية ثورة التعلم العميق. قبل ذلك، اعتقد الجميع أن الشبكات العميقة لا يمكن تدريبها لأن التدرجات تتلاشى. حل هينتون هذه المشكلة بتقنية "التدريب المسبق".
🔧 رؤية تقنية: لماذا الآن؟
كان السؤال المهم: لماذا لم تعمل الشبكات العصبية التي كانت موجودة منذ الستينيات حتى عام 2006؟ الجواب بسيط: كانت ثلاثة أشياء مفقودة - البيانات والقوة الحسابية وخوارزميات أفضل. حتى أوائل العقد الأول من القرن الحادي والعشرين، لم يكن لدينا أي من هذه.
لكن كان لا يزال هناك شيء مفقود: بيانات كافية وقوة حسابية. كان الإنترنت ينمو، لكن لم يكن لدينا بيانات كافية بعد. كانت وحدات معالجة الرسومات لا تزال تُستخدم للألعاب، وليس للذكاء الاصطناعي. كان كل شيء جاهزاً، كان علينا فقط الانتظار...
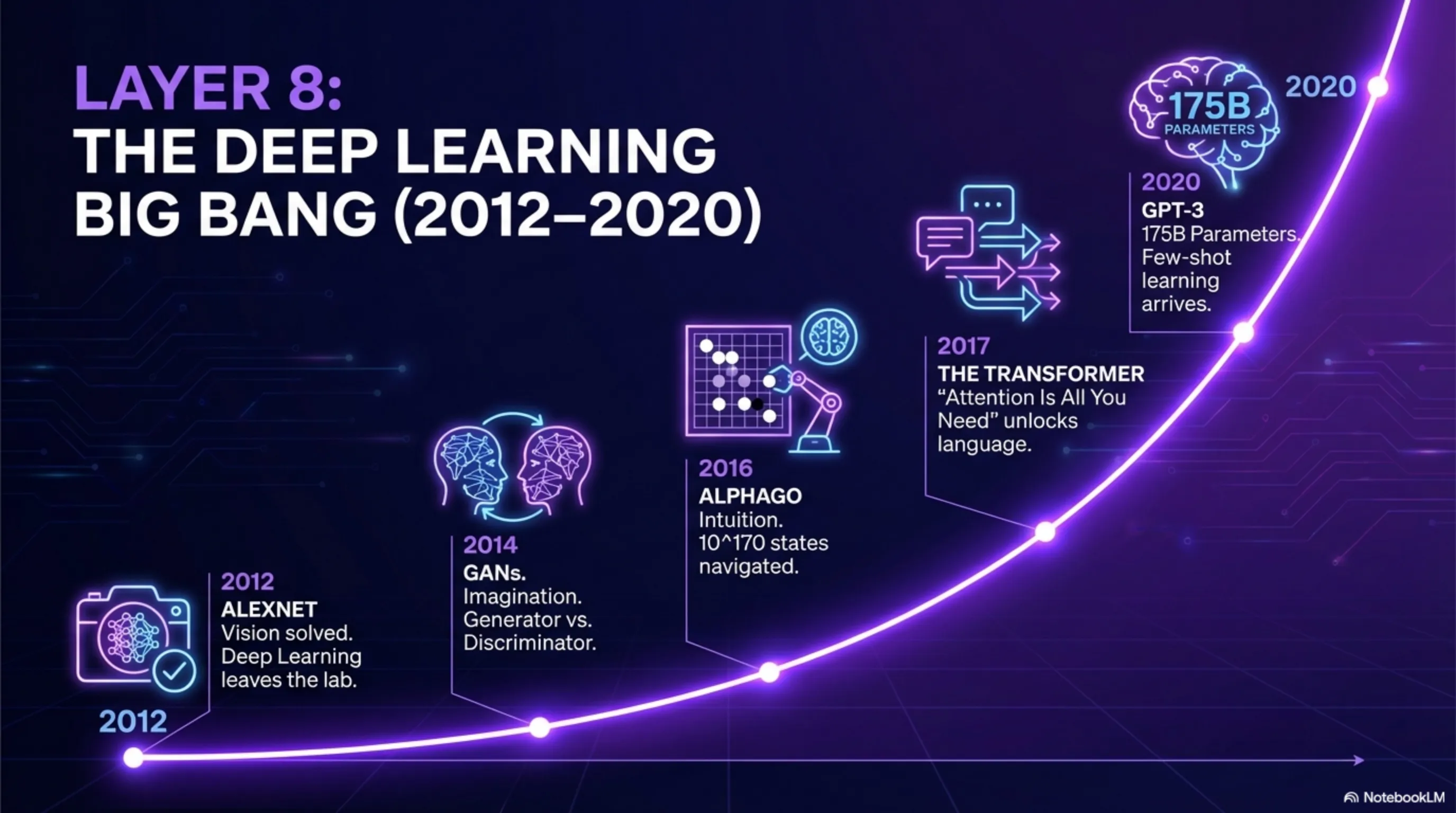
الطبقة 8: الانفجار الكبير - عصر التعلم العميق (2012-2020)
في عام 2012، تغير كل شيء. بنى أليكس كريجيفسكي، طالب الدكتوراه لدى جيفري هينتون، شبكة عصبية عميقة تُسمى AlexNet كسرت الأرقام القياسية في مسابقة ImageNet. كانت دقتها عالية جداً لدرجة أن الجميع صُدموا. كانت هذه اللحظة التي تحول فيها التعلم العميق من بحث أكاديمي إلى تكنولوجيا عملية.
لماذا الآن؟ اجتمعت ثلاثة أشياء:
1. بيانات كثيرة - أنتج الإنترنت والشبكات الاجتماعية مليارات الصور والنصوص. كان لدى ImageNet وحدها 14 مليون صورة موسومة. لم يكن هذا الحجم من البيانات موجوداً من قبل.
2. وحدات معالجة الرسومات - كانت بطاقات الرسومات المصنوعة للألعاب ممتازة لتدريب الشبكات العصبية. تم تدريب AlexNet على بطاقتي NVIDIA GTX 580 - بطاقات تكلف 500 دولار، وليس 500 ألف دولار.
3. خوارزميات أفضل - جعلت تقنيات مثل Dropout (لمنع الإفراط في التكيف) وReLU (دالة تنشيط أسرع) وBatch Normalization التدريب أسهل.
بعد عام 2012، بدأ طوفان من الاختراقات:
2014 - GANs - قدم إيان جودفيلو الشبكات التوليدية التنافسية التي يمكنها إنشاء صور واقعية. كانت الفكرة بسيطة: تتنافس شبكتان عصبيتان - واحدة تنشئ صوراً مزيفة، والأخرى تحاول اكتشاف ما إذا كانت مزيفة أم حقيقية. تجعل هذه المنافسة كلاهما أفضل.
2016 - AlphaGo - هزم نظام DeepMind بطل العالم في لعبة Go. كان هذا أصعب بكثير من الشطرنج لأن Go لديها حالات أكثر (10^170 حالة مقابل 10^120 حالة شطرنج). كان AlphaGo مزيجاً من التعلم العميق وبحث شجرة مونت كارلو.
2017 - Transformer - نشر باحثو Google ورقة "Attention is All You Need" وقدموا بنية Transformer. أصبحت هذه البنية لاحقاً أساس GPT وBERT وجميع نماذج اللغة الكبيرة. يمكن لـTransformer تعلم العلاقات بين الكلمات بشكل أفضل بآلية "الانتباه".
2018 - GPT-1 - أصدرت OpenAI الإصدار الأول من GPT بـ117 مليون معامل. كانت هذه بداية ثورة لا تزال مستمرة.
2020 - GPT-3 - أصدرت OpenAI نموذجاً بـ175 مليار معامل يمكنه كتابة نصوص تشبه البشر، وكتابة التعليمات البرمجية، وحتى الاستدلال. كانت هذه المرة الأولى التي يمكن فيها لنموذج لغوي أداء مهام معقدة دون تدريب محدد (التعلم القليل).
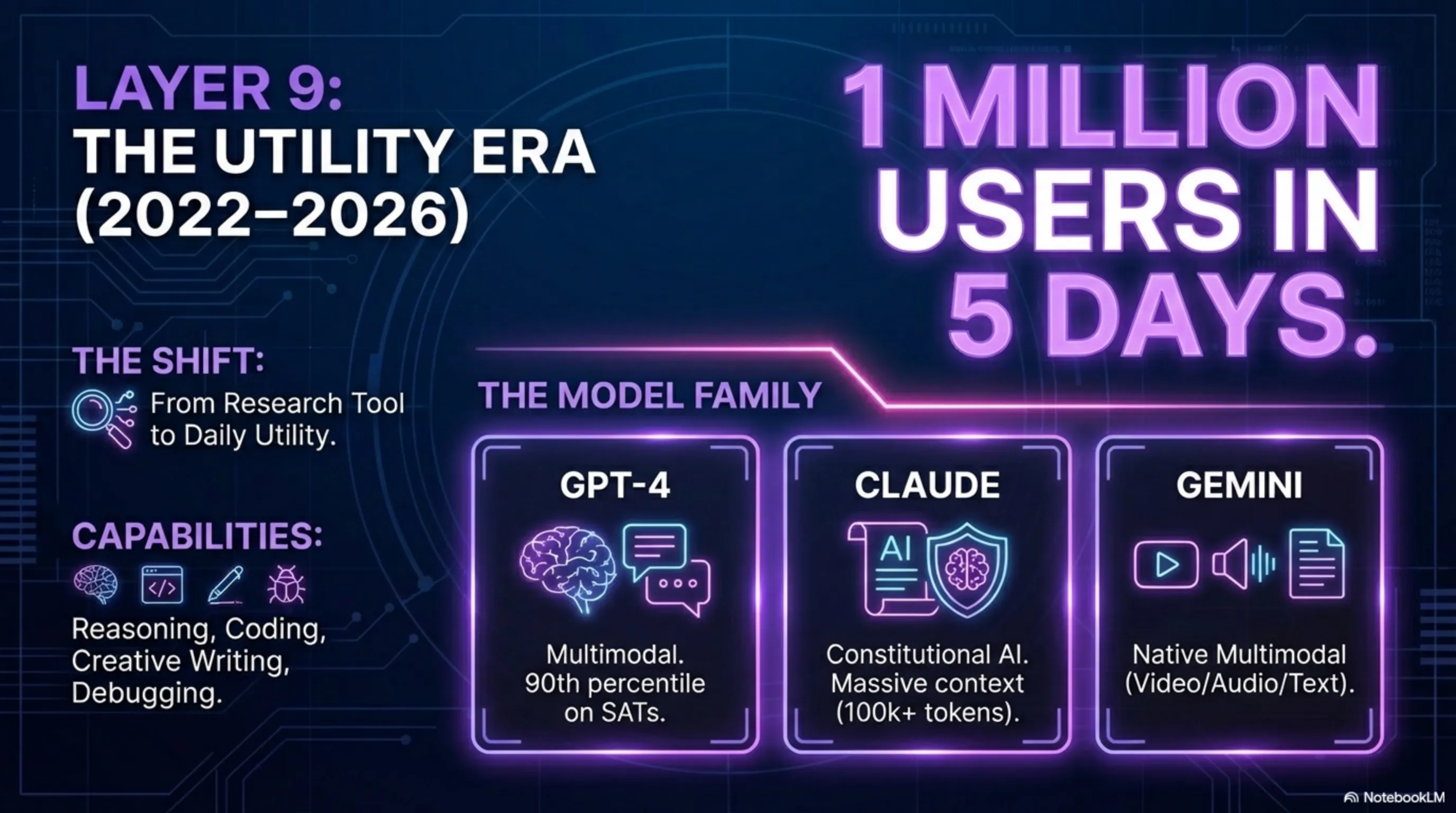
الطبقة 9: عصر ChatGPT - الذكاء الاصطناعي للجميع (2022-2026)
نوفمبر 2022، أصدرت OpenAI ChatGPT وتغير كل شيء. في 5 أيام، مليون مستخدم. في شهرين، 100 مليون مستخدم. أسرع نمو في تاريخ التكنولوجيا. لماذا؟ لأنه لأول مرة، كان ذكاء اصطناعي قوي متاحاً مجاناً وبسهولة للجميع.
لم يكن ChatGPT مجرد روبوت محادثة. كان نظام استدلال يمكنه: كتابة وتصحيح التعليمات البرمجية، وإنشاء المقالات والمحتوى، والإجابة على الأسئلة المعقدة، وترجمة اللغات، وإعطاء أفكار إبداعية، والشرح مثل المعلم.
بعد ChatGPT، جاء طوفان من النماذج الجديدة:
2023 - GPT-4 - نموذج متعدد الوسائط يمكنه أيضاً رؤية الصور. حصل GPT-4 على درجات أعلى من 90٪ من البشر في الاختبارات الموحدة مثل SAT وGRE.
2023 - Claude - بنت Anthropic نموذجاً يركز على "الذكاء الاصطناعي الدستوري" - أي ذكاء اصطناعي أكثر أخلاقية وأماناً. يمكن لـClaude معالجة نصوص طويلة جداً (حتى 100 ألف رمز).
2024 - Gemini - أصدرت Google نموذجاً مصمماً من البداية ليكون متعدد الوسائط. يمكن لـGemini العمل في وقت واحد مع النص والصور والصوت والفيديو.
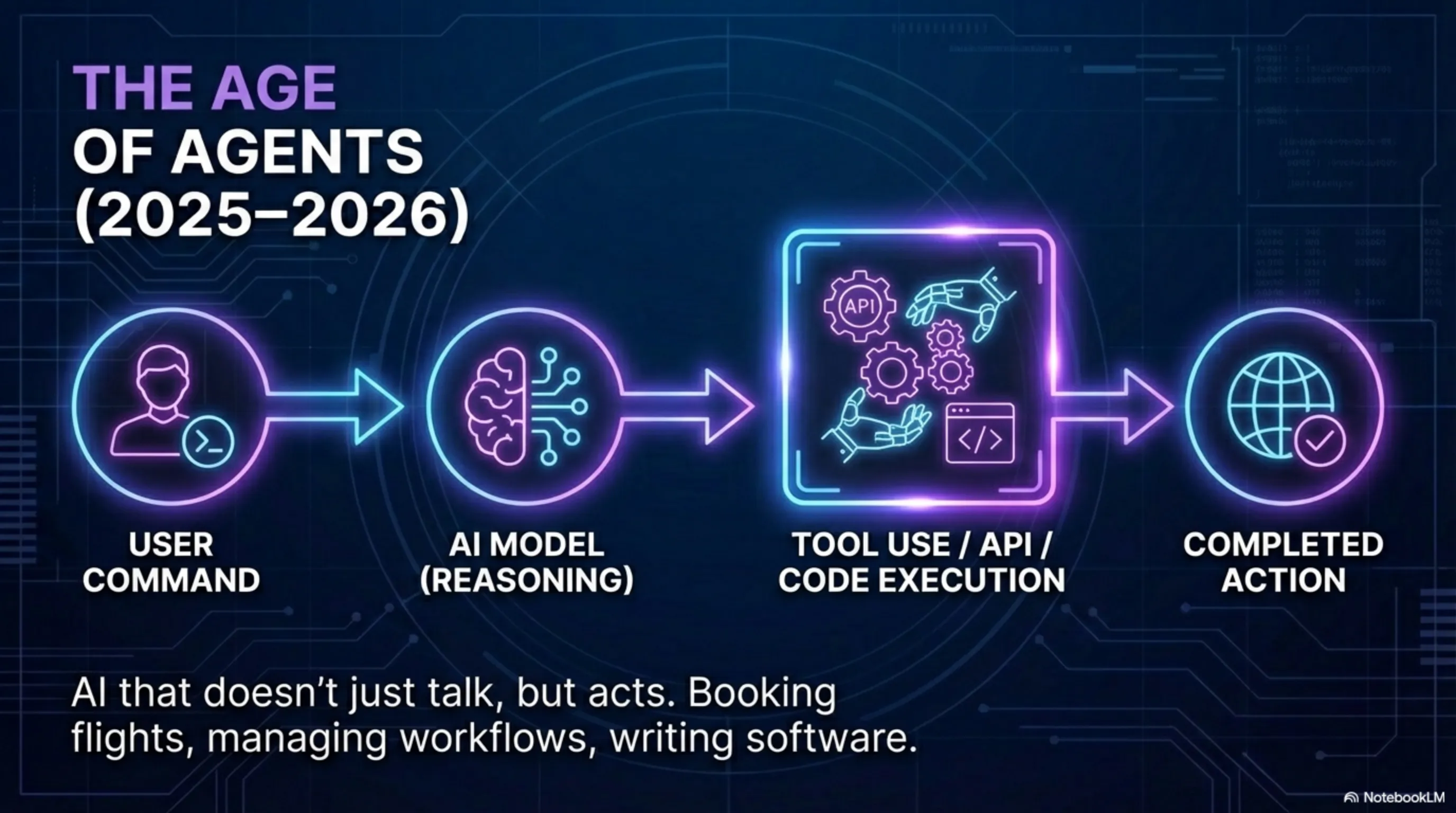
2025-2026 - عصر الوكلاء - لم تعد النماذج الجديدة تستجيب فقط، بل يمكنها اتخاذ إجراءات. يمكنها كتابة وتنفيذ التعليمات البرمجية، والعمل مع واجهات برمجة التطبيقات، وحتى التفاعل مع أدوات أخرى. هذه بداية عصر "وكلاء الذكاء الاصطناعي" - أنظمة يمكنها أداء المهام تلقائياً.
🚨 تحليل حرج: أين نقف؟
إنه عام 2026 ونحن نعمل مع أنظمة بدت مستحيلة قبل 76 عاماً. لكن لا تزال لدينا مشاكل خطيرة: الهلوسة (توليد معلومات خاطئة)، والتحيز (التحيزات في بيانات التدريب)، والقابلية للتفسير (لا نعرف بالضبط كيف يتخذون القرارات)، والسلامة (كيف نضمن عدم فقدان السيطرة). هذه هي التحديات التالية التي يجب حلها.
الخلاصة: من اختبار تورينغ إلى الوكلاء المستقلين
استغرق الأمر 76 عاماً للانتقال من سؤال بسيط ("هل يمكن للآلات أن تفكر؟") إلى أنظمة لا تفكر فحسب، بل يمكنها التعلم والإبداع وحتى الاستدلال. كان هذا الطريق مليئاً بالفشل - شتاءان للذكاء الاصطناعي، ومشاريع بمليارات الدولارات لم تؤدِ إلى أي مكان، وعقود من البحث وصلت إلى طريق مسدود.
لكن ما يجعل هذه القصة مثيرة للاهتمام هو إصرار باحثين مثل جيفري هينتون ويان لوكون ويوشوا بنجيو الذين، حتى في أصعب الأوقات، آمنوا بالشبكات العصبية. كانوا يعلمون أن الدماغ البشري يعمل بالخلايا العصبية، فلماذا لا يمكن محاكاة ذلك بالرياضيات؟
الآن نشهد تحولاً أساسياً. لم يعد الذكاء الاصطناعي مجرد أداة بحثية - لقد أصبح تكنولوجيا عامة تغير كل شيء. من طريقة عملنا، إلى طريقة تعلمنا، إلى طريقة إنشاء المحتوى.
لم يعد السؤال "هل يمكن للآلات أن تفكر؟" أصبح السؤال: "كيف يمكننا العيش مع آلات مفكرة؟"
🎯 ملخص التشريح
1950-1956: اختبار تورينغ وميلاد الذكاء الاصطناعي - حلم الآلات المفكرة
1956-1974: العصر الذهبي - التفاؤل اللامحدود والبرامج الأولى
1974-1980: الشتاء الأول - انهيار الأحلام وقطع الميزانيات
1980-1987: الأنظمة الخبيرة - عودة الأمل بالقواعد اليدوية
1987-1993: الشتاء الثاني - فشل الأنظمة الخبيرة
1990-2010: الثورة الهادئة - التعلم الآلي والشبكات العصبية
2012-2020: الانفجار الكبير - التعلم العميق وAlexNet
2022-2026: عصر ChatGPT - الذكاء الاصطناعي للجميع والوكلاء المستقلون
💼 ملاحظة المفتش: المعدات الموصى بها لعصر الذكاء الاصطناعي
بعد تشريح 76 عاماً من تطور الذكاء الاصطناعي، شيء واحد واضح: هذه التكنولوجيا لن تعود. إذا كنت تريد البقاء في هذا العصر الجديد، فأنت بحاجة إلى أجهزة قوية. هذه هي المعدات التي أوصي بها شخصياً:
🖥️ أنظمة ألعاب قوية
لتشغيل نماذج الذكاء الاصطناعي المحلية (مثل LLaMA أو Stable Diffusion)، تحتاج إلى وحدة معالجة رسومات قوية. بطاقات الرسومات NVIDIA RTX 4080 أو 4090 هي الخيارات الأفضل. نفس البطاقات المستخدمة للألعاب ممتازة للذكاء الاصطناعي.
💻 أجهزة كمبيوتر محمولة احترافية
إذا كنت تريد العمل مع الذكاء الاصطناعي في كل مكان، فأنت بحاجة إلى كمبيوتر محمول قوي. يمكن لأجهزة الكمبيوتر المحمولة للألعاب مع RTX 4070 أو أعلى تشغيل نماذج أصغر. يُوصى بما لا يقل عن 32 جيجابايت من ذاكرة الوصول العشوائي.
⚡ الذاكرة والتخزين
نماذج الذكاء الاصطناعي كبيرة. محرك أقراص SSD NVMe سريع (1 تيرابايت على الأقل) ضروري. للعمل مع مجموعات بيانات كبيرة، 64 جيجابايت من ذاكرة الوصول العشوائي مثالية.
🎮 يمكنك الحصول على كل هذه المعدات من متجر TekinGame - مع ضمان صالح ودعم فني.