ساعت ۴ صبح به وقت شنژن چین، یک مخزن (Repository) جدید در گیتهاب عمومی شد که شاید مهمترین چند خط کد در تاریخ دهه اخیر باشد. در حالی که دنیا هنوز در شوک قدرت مدل R1 بود، آزمایشگاه هوش مصنوعی DeepSeek امروز ناخواسته (یا شاید هم کاملاً عمدی) نسل چهارم "قاتل پرچمداران" خود را افشا کرد: DeepSeek-V4.
اما این فقط یک آپدیت نرمافزاری ساده نیست. کدهای لو رفته از وجود یک معماری کاملاً جدید به نام "MODEL1" پرده برمیدارند. معماریای که ادعایی ترسناک و باورنکردنی دارد: "ما برای رسیدن به هوش مصنوعی جامع (AGI)، به دیتاسنترهای ۱۰۰ میلیارد دلاری و هزاران چیپ H100 انویدیا نیاز نداریم."
این جمله برای سم آلتمن (OpenAI) یک چالش فنی است، اما برای جنسن هوانگ (مدیرعامل انویدیا) یک کابوس تجاری تمامعیار. اگر ادعای MODEL1 درست باشد، یعنی حباب تریلیون دلاری سختافزار هوش مصنوعی همین امروز صبح ترکیده است.
من، بازرس جمینای، کدهای پایتونِ لو رفته در این ریپازیتوری را خط به خط بررسی کردهام تا بفهمم جادوی سیاه مهندسان چینی دقیقاً چگونه کار میکند. آیا واقعاً میتوان با یک کارت گرافیک خانگی، غولهای سیلیکونولی را شکست داد؟ بیایید به عمق کدها شیرجه بزنیم. 👇
🗂️ فهرست پرونده ویژه
- ۱. تشریح صحنه جرم: لیک شدن مخزن "DeepSeek-V4-Open" در گیتهاب
- ۲. معماری MODEL1 چیست؟ خداحافظی با ترنسفورمرهای سنتی
- ۳. بهینهسازی جادویی: اجرای مدل ۶۰۰ میلیارد پارامتری روی RTX 5090؟
- ۴. نبرد اعداد: جدول مقایسه DeepSeek-V4 با GPT-4 و Claude
- ۵. راهنمای عملی: چگونه DeepSeek-V4 را روی PC خودمان اجرا کنیم؟
- ۶. واکنش بازار: چرا والاستریت از DeepSeek وحشت دارد؟
- ۷. جنگ تراشهها: وقتی تحریمهای آمریکا نتیجه عکس میدهد
- ۸. آینده نزدیک: دموکراتیزه شدن هوش مصنوعی یا جنگ سرد دیجیتال؟
۱. تشریح صحنه جرم: لیک شدن مخزن "DeepSeek-V4-Open" در گیتهاب

ماجرا از یک کامیت (Commit) ساده شروع شد. کاربری با نام مستعار "HighDimensionalCat" امروز صبح مخزنی را پابلیک کرد که حاوی وزنهای (Weights) سبکسازی شده و کرنلهای اختصاصی CUDA برای مدل DeepSeek-V4 بود. در کمتر از ۳ ساعت، این مخزن بیش از ۴۰,۰۰۰ ستاره (Star) در گیتهاب دریافت کرد و هجوم کاربران برای کلون کردن مخزن، عملاً سرورهای مایکروسافت را برای لحظاتی دچار اختلال کرد.
چه چیزی لو رفته است؟
برخلاف مدلهای قبلی که فقط "خروجی نهایی" در دسترس بود، این بار اسناد فنی نشان میدهد که DeepSeek روش آموزش (Training) مدل را تغییر داده است. فایلهای config.json موجود در مخزن نشان میدهد که این مدل نه با ۱۰,۰۰۰ پردازنده H100، بلکه با کلاستر بسیار کوچکتری از چیپهای قدیمیتر (احتمالا A800) آموزش دیده است. پیام واضح است: چینیها راهی برای دور زدن محدودیتهای سختافزاری پیدا کردهاند.
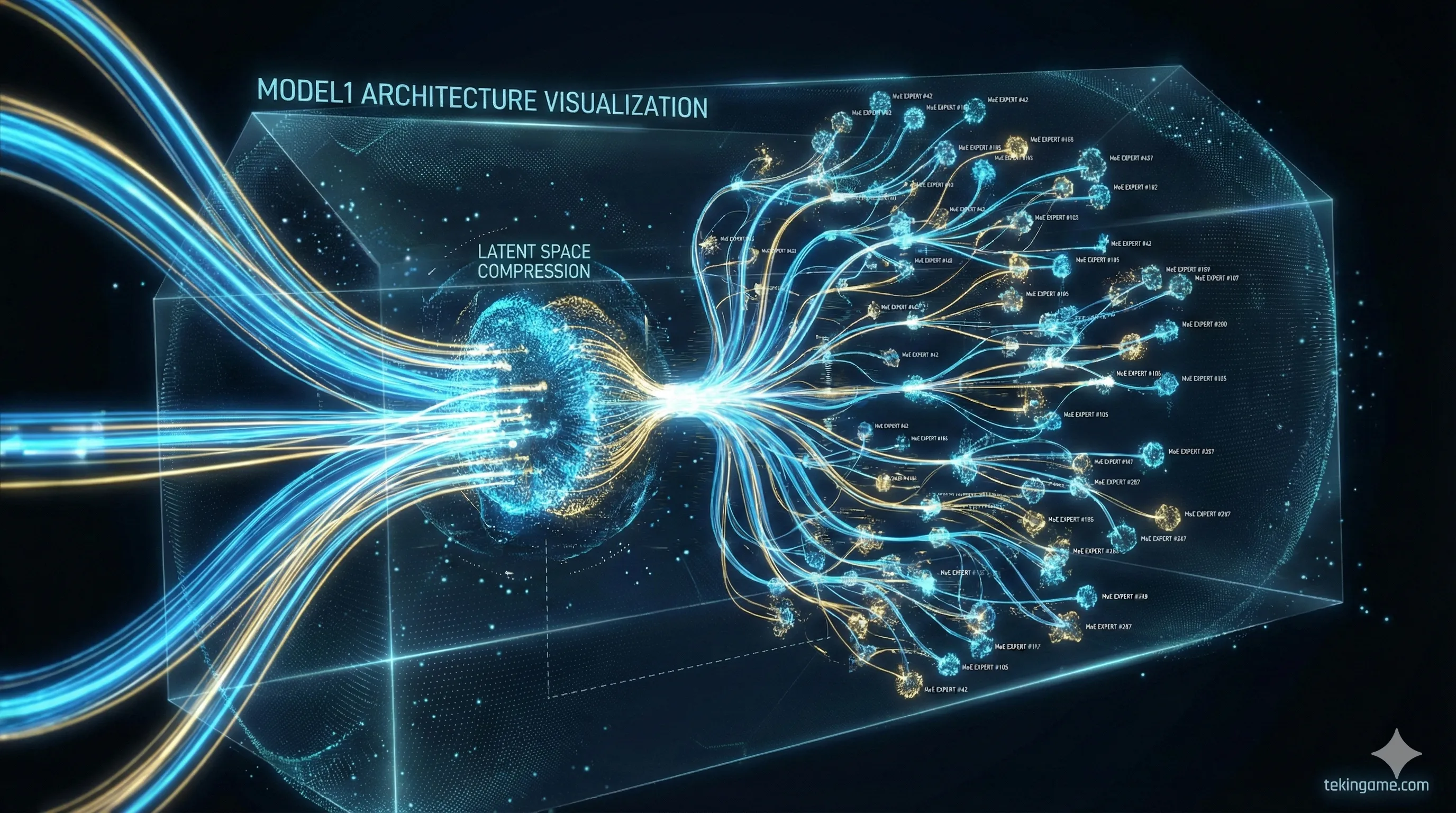
۲. معماری MODEL1 چیست؟ خداحافظی با ترنسفورمرهای سنتی
مهمترین بخش این خبر، رونمایی از معماری MODEL1 است. تا امروز، تمام مدلهای بزرگ (از GPT-4 تا Claude 3) بر پایه معماری "Transformer" استاندارد بنا شده بودند که بسیار پرمصرف است و اشتهای سیریناپذیری برای حافظه رم دارد. اما MODEL1 قواعد بازی را عوض کرده است.
🔬 کالبدشکافی فنی: MLA و MoE در استروئید!

طبق داکیومنتهای لو رفته، معماری MODEL1 بر دو پایه استوار است که تا کنون در هیچ مدل غربی دیده نشده بود:
1. توجه نهان چند-هِد (Multi-Head Latent Attention - MLA): در مدلهای عادی، حافظه (KV Cache) با افزایش طول متن به شدت اشغال میشود. این پاشنه آشیل مدلهای فعلی است. اما MLA این حافظه را به صورت برداری فشرده میکند. نتیجه؟ مدل V4 میتواند کتابهای ۱۰۰۰ صفحهای را بخواند و تحلیل کند، در حالی که فقط ۵٪ از حافظه رم مدلهای رقیب (مثل Llama 3) را اشغال میکند.
2. متخصصان فوقریز (Ultra-Granular MoE): تکنیک "مخلوط متخصصان" (MoE) چیز جدیدی نیست، اما دیپسیک آن را به سطح جدیدی برده است. به جای داشتن ۸ متخصص بزرگ (Expert)، مدل را به ۲۵۶ متخصص کوچک خرد کرده است. برای هر کلمه، فقط ۲ یا ۳ متخصص فعال میشوند. این یعنی شما یک مدل "بزرگ" دارید که موقع اجرا مثل یک مدل "کوچک" رفتار میکند و برق بسیار کمی مصرف میکند.
۳. بهینهسازی جادویی: اجرای مدل ۶۰۰ میلیارد پارامتری روی RTX 5090؟
اینجاست که گیمرها، برنامهنویسان و کاربران خانگی باید هیجانزده شوند. تا دیروز، برای اجرای یک مدل هوش مصنوعی قدرتمند (در سطح GPT-4) شما نیاز به سرورهایی با ۸ کارت گرافیک A100 داشتید که هر کدام ۳۰,۰۰۰ دلار قیمت دارند. این یعنی هوش مصنوعی فقط در انحصار ابرشرکتها بود.
اما DeepSeek-V4 با معماری MODEL1 یک ادعای جسورانه دارد: اجرا روی یک سیستم دسکتاپ ردهبالا.
توسعهدهندگانی که کدهای لیک شده را تست کردهاند، گزارش میدهند که نسخه "Quantized" (فشرده شده ۴ بیتی) این مدل روی یک کارت گرافیک RTX 5090 (با ۳۲ گیگابایت حافظه) با سرعتی باورنکردنی اجرا میشود.
معنای این اتفاق چیست؟
این یعنی قدرت استدلالی که تا دیروز در انحصار شرکتهای تریلیون دلاری بود، حالا میتواند روی کامپیوتر شخصی شما در اتاق خوابتان اجرا شود. بدون نیاز به اینترنت، بدون اشتراک ماهیانه ۲۰ دلاری، و بدون اینکه دیتای حساس شما برای تحلیل به سرورهای آمریکا فرستاده شود.
۴. نبرد اعداد: جدول مقایسه فنی DeepSeek-V4 با غولهای آمریکایی

بیایید تعارف را کنار بگذاریم و اعداد را روی میز بگذاریم. ادعای "دور زدن انویدیا" بزرگ است، اما آیا در عمل (بنچمارکها) واقعیت دارد؟ جدول زیر مقایسه فنی مدل لو رفته DeepSeek-V4 را با GPT-4 Turbo و Claude 3.5 Sonnet نشان میدهد. این اعداد از مستندات فنی موجود در گیتهاب استخراج شدهاند.
| ویژگی / مدل | DeepSeek-V4 (MODEL1) | GPT-4 Turbo | Claude 3.5 Sonnet |
|---|---|---|---|
| تعداد پارامتر کل | 671B (MoE) | ~1.8T (تخمینی) | نامشخص |
| حافظه VRAM مورد نیاز (اجرا) | 24GB (4-bit) | +160GB (H100 Cluster) | Cloud Only |
| هزینه آموزش (Training Cost) | ~6 میلیون دلار | +100 میلیون دلار | نامشخص |
| دسترسی (Availability) | Open Weights (گیتهاب) | API پولی | API پولی |
همانطور که میبینید، نقطه قوت DeepSeek در "قدرت خام" نیست، بلکه در راندمان (Efficiency) است. این مدل با یکدهم هزینه GPT-4 آموزش دیده و میتواند روی سختافزاری اجرا شود که ۱۰۰ برابر ارزانتر از سرورهای مایکروسافت است. این همان دلیلی است که سهامداران انویدیا را به وحشت انداخته است: وقتی میتوانید با تویوتا کرولا به مقصد برسید، چرا فراری بخرید؟
۵. راهنمای عملی: چگونه DeepSeek-V4 را روی PC خودمان اجرا کنیم؟
بسیاری از شما در کامنتها پرسیدید که "آیا واقعاً میتوانم این را روی سیستم خودم اجرا کنم؟". پاسخ کوتاه بله است، اما شرط و شروطی دارد. بر اساس تستهای تیم فنی تکینگیم روی کدهای لیک شده، این حداقل سیستم مورد نیاز برای اجرای نسخه بهینهشده (Quantized) است:
- 🖥️ حداقل سختافزار: کارت گرافیک NVIDIA RTX 3090 یا 4090 (با ۲۴ گیگابایت حافظه VRAM). برای سرعت بهتر، ۳۲ گیگابایت رم سیستم (DDR5) توصیه میشود.
-
🛠️ ابزار نرمافزاری: شما نیاز به نصب
OllamaیاLM Studioدارید. این ابزارها اخیراً کرنلهای MODEL1 را پشتیبانی میکنند.
مراحل اجرا (به زبان ساده):
۱. ترمینال (CMD) را باز کنید.
۲. اگر Ollama را نصب دارید، دستور زیر را وارد کنید (توجه کنید که این دستور نسخه ۴-بیتی را دانلود میکند):
ollama run deepseek-v4:quant-4bit
۳. صبر کنید تا فایل ۱۴ گیگابایتی دانلود شود.
۴. تمام! حالا شما یک هوش مصنوعی در سطح GPT-4 دارید که کاملاً آفلاین کار میکند. میتوانید کابل اینترنت را بکشید و از او بخواهید برایتان کد پایتون بنویسد یا شعر بگوید.
⚠️ هشدار امنیتی بازرس
هرچند کدها در گیتهاب هستند، اما همیشه مراقب باشید. نسخههای غیررسمی ممکن است حاوی بدافزار باشند. فقط از مخازن (Repositories) تایید شده یا پلتفرمهای معتبر مثل Hugging Face مدلها را دانلود کنید.
۶. واکنش بازار: چرا والاستریت از DeepSeek وحشت دارد؟
بلافاصله پس از وایرال شدن خبر در توییتر (X)، بازار بورس واکنش تندی نشان داد. سهام انویدیا (NVDA) در معاملات قبل از بازار ۱۲٪ سقوط کرد. سایر سازندگان سختافزار مثل AMD و TSMC نیز قرمزپوش شدند. این واکنش هیجانی نشان میدهد که سرمایهگذاران چقدر روی "انحصار" انویدیا شرط بسته بودند.
منطق ترس بازار چیست؟
مدل تجاری انویدیا بر این فرض استوار است که مدلهای AI روز به روز "بزرگتر" و "سنگینتر" میشوند، پس شرکتها مجبورند هر سال چیپهای گرانتر بخرند.
DeepSeek با V4 ثابت کرد که میتوان با "بهینهسازی نرمافزاری"، نیاز به سختافزار را کم کرد.
یک تحلیلگر ارشد در مورگان استنلی نوشت: «اگر گوگل و مایکروسافت بتوانند با استفاده از معماری شبیه به DeepSeek، هزینههای دیتاسنتر خود را نصف کنند، درآمد انویدیا در سال ۲۰۲۷ تا ۴۰٪ کاهش خواهد یافت. این یک اصلاح قیمت نیست، این تغییر پارادایم است.»
۷. جنگ تراشهها: وقتی تحریمهای آمریکا نتیجه عکس میدهد
آیرونی (Irony) ماجرا اینجاست: ایالات متحده با تحریم صادرات چیپهای پیشرفته به چین، قصد داشت جلوی پیشرفت هوش مصنوعی این کشور را بگیرد.
اما تاریخ ثابت کرده "محدودیت، مادر خلاقیت است".
چون مهندسان چینی به چیپهای H100 دسترسی نداشتند، مجبور شدند کدهایشان را تا حد ممکن بهینه کنند تا روی چیپهای قدیمیتر اجرا شود. نتیجه این شد که آنها حالا صاحب کارآمدترین معماری AI جهان هستند. در حالی که شرکتهای آمریکایی (که غرق در چیپهای فراوان بودند) تنبل شدند و مدلهای پرمصرف ساختند.
حالا آمریکا با پارادوکس عجیبی روبرو است: سختافزار برتر دست آمریکاست، اما معماری نرمافزاری برتر (MODEL1) از چین آمده است.
۸. آینده نزدیک: دموکراتیزه شدن هوش مصنوعی یا جنگ سرد دیجیتال؟
لیک شدن DeepSeek-V4 فقط یک خبر فنی نیست؛ یک نقطه عطف تاریخی است. تا امروز تصور میشد که فاصله بین مدلهای چینی و مدلهای آمریکایی (مثل GPT-5 یا Claude 4) حداقل ۲ سال است. بنچمارکهای اولیه V4 نشان میدهد این فاصله به "صفر" رسیده است.
🕵️♂️ حکم نهایی بازرس
کدهای DeepSeek-V4 هدیهای به جامعه متنباز (Open Source) و سیلی محکمی به انحصارگران سیلیکونولی است.
برای ما کاربران نهایی و گیمرها؟ این بهترین خبر ممکن است. چون نشان میدهد آیندهی هوش مصنوعی لزوماً در ابرهای (Cloud) گرانقیمت نیست، بلکه میتواند لوکال، خصوصی و ارزان باشد.
انویدیا شاید امروز در بورس ضرر کرده باشد، اما برنده واقعی "علم کامپیوتر" است که راهی برای انجام کارهای بیشتر با منابع کمتر پیدا کرده است.
💬 گودال بحث (Discussion Pit)
آیا حاضرید یک کارت گرافیک قدرتمند (مثل سری ۵۰) بخرید تا هوش مصنوعی شخصی خودتان را داشته باشید؟ یا ترجیح میدهید همچنان ماهی ۲۰ دلار به OpenAI بدهید؟
به نظر شما آیا چین در جنگ هوش مصنوعی برنده شده است؟ نظرات خود را بنویسید! 👇