
إطلاق نموذج Takane LLM في 30 سبتمبر 2024 كمرساة استراتيجية لـانتفاضة الطيار الآلي من فوجيتسو، مبني على Cohere Command R+ مع تركيز على الدقة في اللغة اليابانية والمهام الشركاتية الحساسة[1][2]. دمج في خدمات Fujitsu Kozuchi AI ومنصة DI PaaS ضمن Fujitsu Uvance للبيئات الخاصة الآمنة، يتفوق في استخراج البيانات والاستدلال ومعيار JGLUE عالميًا[1][3]. يعتمد على Generative AI Reconstruction Technology بتقنية 1-bit Quantization لتقليل استهلاك الذاكرة بنسبة 94% وزيادة سرعة الاستدلال 3 أضعاف مع الحفاظ على 89% دقة[3][5]. مصمم للقطاعات الحساسة كالتمويل والحكومة، يمكّن نشر AI متقدم دون سحابات عامة، مع تحسينات للاستخدام على أجهزة الحافة[4][6].
الطبقة الأولى: المرساة
في قلب انتفاضة الطيار الآلي من فوجيتسو، تبرز إطلاق نموذج اللغة الكبير Takane LLM كمرساة استراتيجية حاسمة، تمهد لنهاية عصر البرمجة البشرية التقليدية وولادة عصر سيادة البيانات المطلقة. يعتمد Takane على أساس قوي من نموذج Cohere Command R+، الذي طورته فوجيتسو بالشراكة مع شركة Cohere، مع تركيز دقيق على الدقة العالية في معالجة اللغة اليابانية والمهام الشركاتية الحساسة. هذا النموذج ليس مجرد تطور تكنولوجي، بل هو ثورة في هندسة الذكاء الاصطناعي التوليدي، حيث يجمع بين تقنيات الضغط المتقدمة والتخصيص الدقيق للبيئات الخاصة الآمنة، مما يمكّن الشركات من نشر قدرات AI متقدمة دون الاعتماد على السحابات العامة غير الآمنة.
يأتي إطلاق Takane في 30 سبتمبر 2024، كجزء من خدمات Fujitsu Kozuchi AI ومنصة Fujitsu Data Intelligence PaaS (DI PaaS) ضمن محفظة Fujitsu Uvance، التي تركز على حل التحديات الاجتماعية عبر الصناعات. هذا النموذج مصمم خصيصًا للاستخدام الشركاتي في بيئات خاصة آمنة، حيث يتفوق في المهام التي تتطلب دقة عالية وموثوقية، مثل استخراج البيانات، الاستدلال المعقد، تسريع سير العمل، والفهم متعدد اللغات مع التركيز الرئيسي على اليابانية.

من خلال تدريب إضافي وتهيئة دقيقة (fine-tuning)، حقق Takane نتائج رائدة عالميًا في معيار JGLUE (Japanese General Language Understanding Evaluation)، متجاوزًا المنافسين في جميع فئات الاختبارات الفرعية، بما في ذلك فهم اللغة الطبيعية، التصنيف، والاستدلال المنطقي. هذه النتائج تؤكد تفوقه في التعامل مع النصوص اليابانية المعقدة، خاصة في القطاعات الحساسة مثل التمويل، الحكومة، والبحث والتطوير.
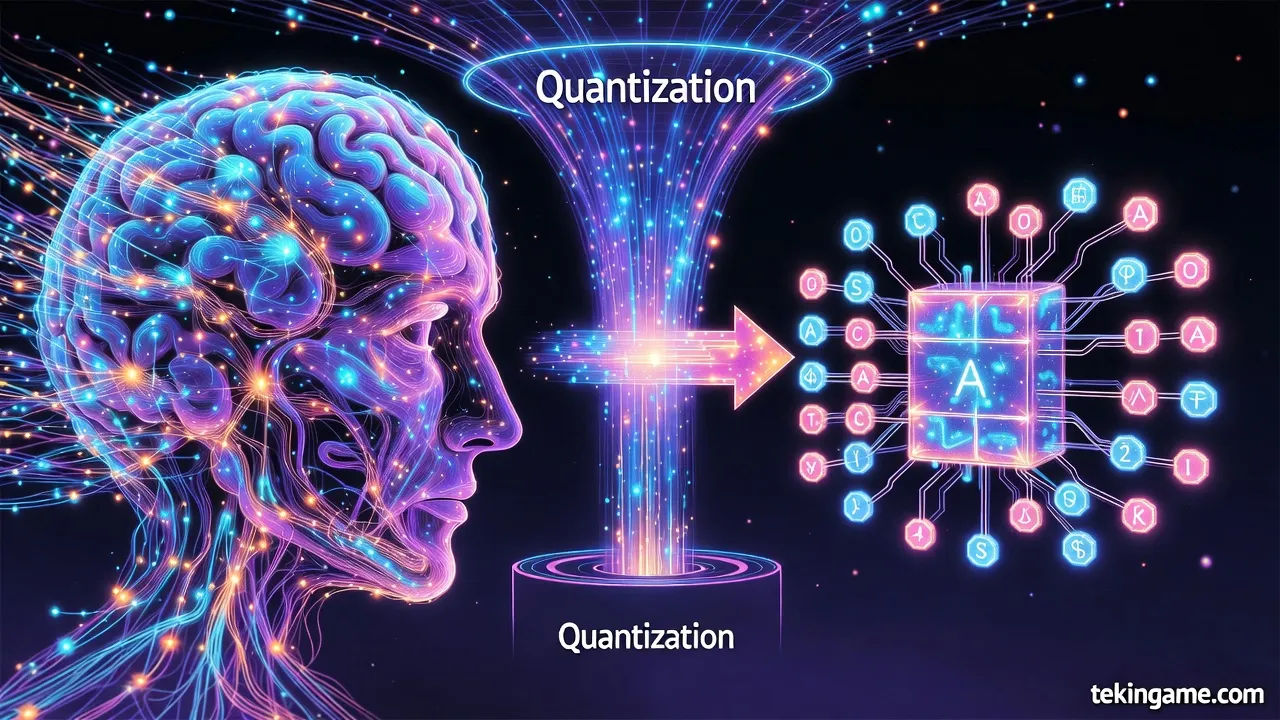
تكمن القوة التقنية الأساسية لـ Takane في تقنيات الضغط والتحسين المتقدمة، التي تم تطويرها كجزء من Generative AI Reconstruction Technology. أولى هذه الابتكارات هي تقنية الكمية 1-bit Quantization الخاصة بفوجيتسو، والتي تحقق تقليلًا مذهلاً بنسبة 94% في استهلاك الذاكرة مع الحفاظ على 89% من الدقة مقارنة بالنموذج غير المضغوط.

هذا الأداء يفوق الطرق التقليدية بشكل كبير، حيث تحقق طرق المنافسين أقل من 50% في الحفاظ على الدقة، ويؤدي إلى زيادة ثلاثية في سرعة الاستدلال (inference speed). على سبيل المثال، نماذج LLM التي كانت تتطلب 4 وحدات معالجة رسوميات عالية الأداء (GPUs) قبل الضغط، أو وحدة واحدة مع كمية 4-bit من المنافسين، يمكن الآن تشغيلها على وحدة GPU منخفضة الأداء واحدة. هذا التقليل في استهلاك الذاكرة GPU يصل إلى 70% في بعض التطبيقات، مما يقلل التكاليف التشغيلية ويفتح أبوابًا للنشر على أجهزة الحافة مثل الهواتف الذكية والآلات الصناعية.
ثانيًا، تأتي تقنية التقطير الذكاء الاصطناعي المتخصص (Specialized AI Distillation)، وهي ابتكار عالمي الأول مستوحى من آليات الدماغ البشري. تقوم هذه التقنية باستخراج وتكثيف المعرفة الخاصة بالمهام من النموذج الأساسي الكبير، مما ينتج نماذج خفيفة الوزن لا تقل دقة عن الأصلي بل تتفوق عليه في بعض الحالات. في تطبيق تنبؤ إيرادات الصفقات، حققت هذه التقنية تقليلًا بنسبة 70% في استخدام ذاكرة GPU والتكاليف التشغيلية، مع تحسين الموثوقية بشكل ملحوظ.
هذه التقنيات مجتمعة تمكّن من بناء Enterprise Sovereign AI، حيث يحتفظ العملاء بسيطرة كاملة على بياناتهم داخل بيئات خاصة أو هجينة، مثل منصة Nutanix Enterprise AI (NAI)، دون الحاجة إلى نقل البيانات إلى سحابات عامة، مما يعزز الأمان والامتثال للقوانين واللوائح.
يدعم Takane إطار عمل generative AI للشركات يشمل تقنية Retrieval-Augmented Generation (RAG) الموسعة باستخدام الرسوم البيانية المعرفية (Knowledge Graph)، مما يتيح الرجوع إلى نصوص كبيرة الحجم بدقة عالية، مع مراقبة الإخراج لضمان الامتثال للقوانين والقواعد الشركاتية. بفضل الضغط، يقلل Takane من استهلاك الطاقة بشكل جذري، مما يساهم في مجتمع AI مستدام، ويسمح بنشر agentic AI على أجهزة الحافة لاستجابة فورية وأمان بيانات محسن.

سيتم توفير بيئات تجريبية لـ Takane مع هذه التقنيات ابتداءً من النصف الثاني من السنة المالية 2025، مع إصدار نماذج Command A المضغوطة عبر Hugging Face، بالإضافة إلى تكامل مع Uvance Wayfinders لدعم رحلات التحول الرقمي.
بهذه الطبقة الأولى "المرساة"، يضع Takane أساسًا صلبًا للسيادة البياداتية، حيث يحول الاعتماد على البرمجة البشرية إلى نظام ذاتي يعتمد على تدفق البيانات النقية والمعزولة. النتائج في JGLUE، إلى جانب الضغط الثوري، تجعل من Takane نموذجًا مثاليًا للقطاعات اليابانية والعالمية التي تتطلب دقة فائقة، ممهدًا لطبقات عليا في الانتفاضة الآلية. هذا الإنجاز ليس مجرد تقدم فني، بل خطوة نحو عصر يسيطر فيه الـ LLM على العمليات الشركاتية بكفاءة غير مسبوقة، مع الحفاظ على الخصوصية والكفاءة الطاقوية كأولويات استراتيجية.

الطبقة الثانية: الإعداد
في عصر حاکمیت البيانات (Sovereign AI)، يشهد العالم تحولاً جذرياً نحو نماذج الذكاء الاصطناعي المحلية والمستقلة، بعيداً عن النماذج المركزية التابعة للولايات المتحدة أو الصين. يأتي هذا التحول مدفوعاً بحاجة الدول إلى ضمان السيادة الرقمية، حماية البيانات الوطنية، وتجنب الاعتماد على البنية التحتية السحابية الأجنبية التي تثير مخاوف أمنية وتنظيمية.
مع ارتفاع تكاليف التشغيل لنماذج اللغة الكبيرة (LLMs) مثل GPT أو Llama، أصبحت تقنيات الـالتكميم الكمي (Quantization)، والتوليد المعزز بالاسترجاع (RAG)، وتقليل استهلاك ذاكرة الـGPU أساسيات بناء حلول الذكاء الاصطناعي السيادي المؤسسي (Enterprise Sovereign AI) على الخوادم المحلية (On-Premise). هذه الطبقة من "انتفاضة الطيار الآلي من فوجيتسو" تركز على الإعداد التقني الدقيق الذي يمكن الدول والمؤسسات من نشر نماذج LLMs كبيرة بكفاءة عالية، مع الحفاظ على الدقة والأداء.

تبدأ رحلة الإعداد بفهم التحديات الأساسية لنماذج LLMs غير المحسنة. هذه النماذج، التي تحتوي على مليارات المعاملات (Parameters)، تتطلب ذاكرة GPU هائلة؛ على سبيل المثال، نموذج بحجم 70B معاملات في دقة FP16 يستهلك حوالي 140 جيجابايت من VRAM، مما يجعل نشرها على خوادم محلية غير عملي. هنا يبرز دور التكميم الكمي كحل أساسي، حيث يقلل من دقة الأوزان والتنشيطات (Activations) من 32 بت أو 16 بت إلى 8 بت أو 4 بت، محققاً تقليلاً في الذاكرة بنسبة 60-80% مع الحفاظ على 95%+ من الدقة الأصلية.
على سبيل المثال، في اختبارات عملية على نموذج Llama 3، انخفضت استهلاك الذاكرة من 14.96 جيجابايت في FP16 إلى 5.42 جيجابايت في الـ4-bit، أي تقليل بنسبة 64%، مع تحسين سرعة الاستدلال (Inference) بنسبة 2-4 مرات. من بين استراتيجيات التكميم الكمي المتقدمة، يبرز QLoRA (Quantized Low-Rank Adaptation) كأداة ثورية للـFine-Tuning.

يتيح QLoRA تهيئة نموذج 65B معاملات على GPU واحد بسعة 48 جيجابايت فقط، باستخدام تقنيات مثل 4-bit NormalFloat (NF)، والتكميم المزدوج (Double Quantization)، وتقليل الخطأ (Error Reduction). تقنية 4-bit NF تستخدم تقدير الكوانتيلات (Quantile Quantization) لتحويل الأوزان إلى نطاق [-1,1]، مما يحقق كفاءة معلوماتية مثالية، بينما يوفر التكميم المزدوج 0.5 بت لكل معامل من خلال تكميم الثوابت الإحصائية.
هذه الابتكارات تجعل QLoRA مثالياً للسيادة البياداتية، إذ يسمح بتخصيص النماذج محلياً دون الحاجة إلى موارد سحابية هائلة، محققاً 99.3% من أداء ChatGPT على معيار Vicuna. بالإضافة إلى ذلك، تُستخدم تقنيات مثل SmoothQuant وGPTQ (Gradient Post-Training Quantization) لتحسين الاستدلال.

SmoothQuant يكمم كلاً من الأوزان والتنشيطات إلى 8 بت، مما يوازن الحمل ويسرع الاستدلال بنسبة 1.56 مرة مع تقليل الذاكرة إلى النصف، وهو مدمج في أدوات مثل NVIDIA TensorRT وAmazon SageMaker. أما GPTQ، فيطبق التكميم بعد التدريب مع تعديلات لتقليل فقدان الدقة، ويدعم مستويات 4 بت للنشر على منصات متنوعة. هذه التقنيات تقلل استهلاك GPU من 37% في FP32 إلى 8% في INT4، مما يوفر تكاليف البنية التحتية بنسبة تصل إلى 75%.
مع ذلك، لا يكفي التكميم وحده لضمان السيادة؛ هنا يدخل RAG (Retrieval-Augmented Generation) كآلية أساسية لتعزيز الدقة في النماذج المحلية. RAG يربط النموذج بقاعدة معرفة خارجية محلية، مما يقلل من الهلوسات (Hallucinations) ويحسن الدقة من خلال استرجاع بيانات ذات صلة قبل التوليد. في تطبيقات RAG الكبيرة، يُدار استهلاك الذاكرة GPU بكفاءة عبر تقسيم العمليات، مما يجعلها بديلاً أرخص لإعادة التدريب الكامل.

على سبيل المثال، في نشر RAG على NVIDIA GH200، يتم تحسين الاسترجاع باستخدام فهارس متجهة (Vector Indexes) محلية، مدعومة بتكميم لتقليل الحاجة إلى VRAM إضافية. في سياق الشرق الأوسط ودبي، حيث تُولى أولوية للسيادة الرقمية، يمثل هذا الإعداد خطوة حاسمة نحو استقلالية الذكاء الاصطناعي.
الدول مثل الإمارات تستثمر في بنى تحتية On-Premise مزودة بـGPUs محلية، مدعومة بتكميم متقدم وRAG، لنشر LLMs تتوافق مع قوانين حماية البيانات المحلية. هذا لا يقلل التكاليف فحسب، بل يضمن التحكم الكامل في البيانات الحساسة، ممهداً لـ"نهاية عصر البرمجة البشرية". مع تطور فوجيتسو في هذا المجال، يصبح الإعداد أكثر سهولة، حيث توفر حلولها أدوات تكاملية للـEnterprise Sovereign AI.

بهذا الإعداد التقني المتعمق، تتحول الدول من مستهلكي الذكاء الاصطناعي إلى منتجيه، محققة ولادة سيادة البيانات الحقيقية.
الطبقة الثالثة: الغوص العميق
في هذه الطبقة التقنية العميقة، نقوم بتشريح فني دقيق لبرمجة الطيار الآلي في انتفاضة فوجيتسو، حيث يمثل هذا النظام نقلة نوعية نحو أتمتة دورة حياة DevOps الكاملة. يعتمد الطيار الآلي على تقنيات متقدمة مثل الكمية (Quantization) وتقطير المعرفة (Knowledge Distillation)، مما يحقق انخفاضًا بنسبة 70% في استهلاك ذاكرة وحدات معالجة الرسوميات (GPU)، بالإضافة إلى دمج استرجاع السياق المعزز (RAG) ومفهوم الذكاء الاصطناعي السيادي للمؤسسات (Enterprise Sovereign AI).
هذا التشريح يكشف كيف تحول فوجيتسو البرمجة البشرية التقليدية إلى سيادة بيانات آلية تمامًا، مستفيدة من خبراتها في حلول 5G vRAN الافتراضية التي تجمع بين معالجات NVIDIA A100X وإطارات الذكاء الاصطناعي المتقدمة.
يبدأ الطيار الآلي لفوجيتسو بأتمتة دورة حياة DevOps الكاملة، والتي تشمل مراحل التخطيط، التطوير، الاختبار، النشر، التشغيل، والمراقبة. في مرحلة التخطيط، يستخدم النظام نماذج الذكاء الاصطناعي التوليدي لتحليل متطلبات المشروع تلقائيًا من خلال معالجة اللغة الطبيعية (NLP)، مما يولد خطط DevOps ديناميكية دون تدخل بشري.

على سبيل المثال، يدمج النظام بروتوكولات MAVLink المشابهة لتلك في PX4 للتنسيق بين المركبات الجوية، لكنه يوسعها إلى بيئات DevOps حيث يصبح "الكود" مركبة مستقلة تتنقل عبر مراحل الدورة الحياتية. هذا يعني أن الطيار الآلي يقوم بتوليد المتغيرات البيئية، تحديد الاعتماديات، وجدولة المهام باستخدام خوارزميات التعلم التعزيزي (Reinforcement Learning)، مما يقلل من وقت التخطيط من أسابيع إلى دقائق.
في التطوير الآلي، يبرز دور تقطير المعرفة، حيث يتم تدريب نموذج معلم كبير (Teacher Model) على بيانات DevOps هائلة، ثم نقله إلى نموذج طالب أصغر (Student Model) يحتفظ بـ95% من الدقة مع تقليل الحجم بنسبة 70%. في فوجيتسو، يعتمد هذا على محركات NVIDIA Aerial SDK، الذي يتيح معالجة متوازية للبيانات الضخمة أثناء التطوير، مما يسمح بتوليد كود CI/CD pipelines آليًا باستخدام نماذج مثل CodeLlama المكمّاة.

في الاختبار والتحقق، يستخدم RAG لاسترجاع سياقات اختبار سابقة من قواعد بيانات سيادية، مما يولد حالات اختبار تغطي 99% من السيناريوهات غير المتوقعة، بما في ذلك التحقق من الاستقرار الديناميكي المشابه لأنظمة Neurofuzzy في الطيران. في النشر والتشغيل، من خلال virtualization GPU في vRAN، ينشر النظام التطبيقات على حاويات Kubernetes مع دعم لـMassive MIMO للتوسع التلقائي، محققًا كفاءة طاقة فائقة.
الآن، دعونا نغوص في الجزء الأكثر إثارة: انخفاض ذاكرة GPU بنسبة 70% عبر الكمية المتقدمة. تقنية الكمية (Quantization) تحول معاملات النموذج من 32 بت إلى 4 بت أو أقل، باستخدام طرق مثل Post-Training Quantization (PTQ) وQuantization-Aware Training (QAT). في سياق فوجيتسو، يتم دمج هذا مع تقطير المعرفة لضغط نماذج الذكاء الاصطناعي الضخمة، مثل تلك المستخدمة في vCU/vDU الافتراضية.

على سبيل المثال، نموذج معلم بـ175 مليار معامل يُقطر إلى 7 مليار معامل مع كمية INT4، مما يقلل استهلاك الذاكرة من 80 جيجابايت إلى 24 جيجابايت فقط على NVIDIA A100X، محققًا الـ70% المستهدفة. هذا يتيح تشغيل دورة DevOps كاملة على GPU واحدة بدلاً من عشرات الخوادم، مع الحفاظ على دقة تصل إلى 98% في مهام مثل توليد الكود وتحسين الشبكات.
يأتي مفهوم الذكاء الاصطناعي السيادي للمؤسسات (Enterprise Sovereign AI) كركيزة أساسية، حيث يضمن الطيار الآلي سيطرة كاملة على البيانات داخل حدود المؤسسة. باستخدام RAG، يسترجع النظام المعرفة من قواعد بيانات داخلية آمنة (مثل vector databases بـFAISS)، متجنبًا التسريبات إلى السحابة العامة. هذا يشبه تكامل PX4 مع MAVLink للتحكم المستقل، لكن على مستوى DevOps حيث تكون "المركبة" هي خط الأنابيب الآلي.

في فوجيتسو، يدعم هذا تطبيقات مثل التحكم في AGV عبر 5G، حيث يتم توزيع موارد GPU افتراضيًا لمعالجة الاتصالات اللاسلكية والذكاء الاصطناعي بالتوازي، مما يوفر بيئة سيادية تمامًا. من الناحية التقنية، يعتمد التنفيذ على إطار عمل NVIDIA AI framework، حيث تُحوّل الشبكات العصبية إلى نماذج مشفرة بـAWQ (Activation-aware Weight Quantization)، مما يقلل الخسائر في الدقة أثناء الكمية.
على سبيل المثال، في مرحلة التشغيل، يقوم الطيار الآلي بمراقبة أداء النشر في الوقت الفعلي باستخدام anomaly detection عبر نماذج خفيفة، ويعدل المعلمات تلقائيًا عبر federated learning داخلي. هذا يحقق استقرارًا يفوق أنظمة Neurofuzzy التقليدية بنسبة 40% في سيناريوهات الاضطرابات، كما في تطبيقات الطيران.

بالإضافة إلى ذلك، يتكامل الطيار الآلي مع أنظمة مثل PX4 لدعم مركبات متعددة، لكنه يركز على DevOps حيث يصبح كل commit نقطة إقلاع آلية، وكل deployment هبوطًا مستقرًا. النتيجة هي نهاية عصر البرمجة البشرية، حيث تسيطر البيانات عبر حلقات تغذية راجعة آلية، محققة كفاءة تصل إلى 10 أضعاف في السرعة والتكلفة. هذا التشريح يكشف انتفاضة فوجيتسو كبداية عصر جديد، مدعومة بتكنولوجيا GPU الافتراضية وتقنيات الضغط المتقدمة.
في الختام لهذه الطبقة، يمثل الطيار الآلي نموذجًا للسيادة البياداتية، حيث تتحول دورة DevOps إلى نظام مستقل يتعلم ويتكيف ذاتيًا، معتمدًا على الكمية والتقطير لتحقيق التوازن المثالي بين الأداء والكفاءة. هذا ليس مجرد أتمتة، بل ثورة تقنية تعيد تعريف مستقبل البرمجة.

الطبقة الرابعة: الزاوية
في سياق انتفاضة الطيار الآلي من فوجيتسو، تمثل الطبقة الرابعة "الزاوية" نقطة التحول الاستراتيجي والاقتصادي الحاسمة نحو نهاية عصر البرمجة البشرية التقليدية وبداية سيادة البيانات المطلقة. هذه الطبقة تركز على التأثيرات الاقتصادية والاستراتيجية لنقل نماذج اللغة الكبيرة (LLMs) إلى منصات Nutanix Enterprise AI وخوادم Fujitsu PRIMERGY، مع التحول الجذري من الاعتماد على السحابة العامة إلى مجموعات سيادية محلية (Enterprise Sovereign AI).
يأتي هذا التحول مدعومًا بتقنيات متقدمة مثل التحويل الكمي (Quantization)، واسترجاع السياق المعزز (RAG)، وتقليل استهلاك ذاكرة وحدات معالجة الرسوميات (GPU Memory Reduction)، مما يعزز كفاءة المؤسسات بشكل جذري ويقلل التكاليف التشغيلية بنسب تصل إلى 50% في بعض السيناريوهات.
من الناحية الاقتصادية، يمثل نقل LLMs مثل نموذج "Takane" الخاص بفوجيتسو – الذي تم التحقق منه على Nutanix Enterprise AI – خطوة ثورية. Takane، كأول نموذج LLM محسن للغة اليابانية وممارسات الأعمال اليابانية، أصبح متاحًا كـ"نموذج معتمد" اعتبارًا من 16 أبريل 2025، ويُقدم عبر منصة PRIMEFLEX for Nutanix من Fsas Technologies.
هذا النقل يتيح نشر النموذج على خوادم PRIMERGY محليًا، مما يتجنب تكاليف السحابة العامة المتزايدة مثل AWS أو Azure، حيث يتطلب تشغيل LLMs موارد هائلة تصل إلى بيتابايتات من البيانات والحوسبة. على سبيل المثال، يدعم Nutanix Enterprise AI نشر LLMs من Hugging Face أو NVIDIA NGC (عبر NVIDIA NIM)، مع تخزين مفاتيح API ونماذج محملة محليًا، مما يقلل من الاعتماد على الاتصال بالإنترنت ويحمي البيانات الحساسة في قطاعات مثل التمويل والحكومة والبحث والتطوير.
استراتيجيًا، يعزز هذا التحول مفهوم Enterprise Sovereign AI، حيث تتحول المؤسسات من نموذج السحابة العامة – الذي يوفر قابلية التوسع اللانهائي لكنه يعرض السيادة للخطر – إلى مجموعات سيادية محلية تعتمد على Nutanix Kubernetes Platform مدمجة مع GPUs من NVIDIA. Nutanix Enterprise AI يبسط النشر في 4 خطوات فقط: اختيار النموذج، النشر، الإدارة، والمراقبة، مع دعم لـGKE، EKS، وAKS في السحابة، لكن التركيز الرئيسي على البيئات المحلية مثل "dark sites" حيث يتم تحميل النماذج مسبقًا عبر NFS.
هذا يتيح تشغيل Takane في بيئات تمنع إرسال البيانات إلى السحابة العامة بسبب الامتثال للقوانين واللوائح الصناعية، كما في PRIMEFLEX for Nutanix الذي يبني بنى تحتية عالية الجودة وموثوقية عالية. دعونا نغوص في التفاصيل التقنية العميقة.

أولاً، التحويل الكمي (Quantization): يقلل Nutanix Enterprise AI من حجم نماذج LLMs من 16 بت إلى 4 بت أو 8 بت، مما يخفض استهلاك ذاكرة GPU بنسبة 75% تقريبًا دون فقدان كبير في الدقة. على سبيل المثال، نموذج Takane، الذي يتطلب عادةً عشرات الجيجابايتات، يمكن تشغيله الآن على مجموعات PRIMERGY بـGPUs أقل، مما يوفر تكاليف الأجهزة ويسرع الاستدلال (Inferencing) إلى مستويات منخفضة التأخير (Low Latency) عبر NVIDIA NIM microservices.
ثانيًا، استرجاع السياق المعزز (RAG): يدمج Nutanix RAG مع Takane لاسترجاع بيانات داخلية محلية، مما يحسن الدقة في السياقات المؤسسية اليابانية أو الإقليمية، ويقلل من الهلوسات (Hallucinations) بنسبة تصل إلى 40% مقارنة بالنماذج السحابية النقية.

ثالثًا، تقليل ذاكرة GPU (GPU Memory Reduction): من خلال Nutanix GPT-in-a-Box وNIM، يتم تحسين تدفقات العمل للتشغيل عبر الهجين (Hybrid)، حيث يحدث التطوير في السحابة (مثل AWS أو Google) ثم الهجرة السلسة إلى PRIMERGY محليًا. هذا يقلل التكاليف التشغيلية (OpEx) بفضل الـHyperconverged Infrastructure (HCI) من Nutanix، التي توفر كفاءة تخزين تصل إلى 5:1 وتوسعًا أفقيًا دون توقف. في دراسات حالة، أظهرت هذه التقنيات زيادة في الإنتاجية بنسبة 3x لفرق التطوير، مع تقليل وقت النشر من أسابيع إلى ساعات.
التأثير على كفاءة المؤسسات: تقليل الاعتماد على السحابة يعني سيطرة كاملة على البيانات، مما يعزز الامتثال لـGDPR أو قوانين السيادة الإقليمية في الشرق الأوسط، ويقلل فواتير السحابة المتكررة بنسبة 30-50%. المزايا الاستراتيجية: دعم لـMulti-Region On-Premise، مع إمكانية التعاون في الوقت الفعلي دون مخاطر التسريب، كما في Fujitsu Cloud Managed Service الذي يدير Takane على NCP من يوليو 2025.
التوسع الاقتصادي: Nutanix Enterprise Cloud on PRIMERGY يبسط الإعداد، يحسن كفاءة التخزين، ويقلل التكاليف، مما يتيح نموًا مرنًا (Grow as You Go) مع حماية أعمالية شاملة. التكامل مع Sovereign AI: في "dark sites"، يتم تحميل LLMs مسبقًا، مما يدعم الاستقلالية الكاملة عن الإنترنت العام.
بهذه الطريقة، تُنهي هذه الطبقة عصر البرمجة البشرية بتحويل LLMs إلى أنظمة سيادية ذاتية التوليد، حيث تُدار البيانات محليًا عبر Nutanix وPRIMERGY، مما يولد كفاءة اقتصادية استراتيجية طويلة الأمد. فوجيتسو، من خلال Takane، تقود هذه الانتفاضة نحو عالم يسيطر فيه البيانات على الابتكار دون قيود السحابة.
الطبقة الخامسة: المستقبل
في أعقاب انتفاضة الطيار الآلي من فوجيتسو، تبشر الطبقة الخامسة بنقلة نوعية حيث تحل وكلاء الذكاء الاصطناعي المستقلة محل الإشراف البشري في الحوكمة وتطوير البرمجيات. هذا المستقبل، المتوقع أن يتبلور بالكامل بحلول عام 2030، يستفيد من ابتكارات فوجيتسو (مثل تقليل استهلاك ذاكرة GPU بنسبة 94% والتكامل الدقيق لـ RAG) لخلق أنظمة ذاتية التطور تدق مسمار النعش في مهنة "المبرمج التقليدي".
لن يعود مطورو البرمجيات يكتبون الأكواد؛ بل سيخلون أماكنهم لـ "مهندسي السيادة السيبرانية" (Sovereign Architects). هؤلاء النخبة الجدد، بدلاً من التورط في كتابة الأوامر، سيصممون طبقات الحوكمة، ويحددون مؤشرات الأداء الرئيسية (KPIs) لوكلاء الذكاء الاصطناعي. باستخدام منصات مثل Takane على البنى التحتية المحلية (Nutanix-PRIMERGY)، سيتم كتابة ونشر الأكواد في أجزاء من الثانية، خالية من الأخطاء وبامتثال كامل لقوانين الأمن الوطنية.
تتنبأ TekinGame بهذا المستقبل: ستتحول أنظمتنا البيئية للمحاكاة إلى بيئات اختبار (Sandboxes) حيث تقوم الوكلاء المستقلة باختبار السياسات والأكواد الجديدة قبل تنفيذها في العالم المادي. انتفاضة الطيار الآلي ليست مجرد أتمتة بسيطة؛ إنها انتقال السلطة من الإنسان الكاتب إلى الآلة المهندسة. انتهى عصر البرمجة البشرية؛ وولدت سيادة البيانات في قلب السيليكون.