في الساعة 4:00 فجراً بتوقيت شنتشن بالصين، تم نشر مستودع (Repository) جديد على GitHub قد يحتوي على أهم أسطر برمجية في هذا العقد. بينما كان العالم لا يزال يترنح من صدمة قوة نموذج R1، قام مختبر DeepSeek للذكاء الاصطناعي عن غير قصد (أو ربما بشكل متعمد تماماً) بتسريب الجيل الرابع من "قاتل الهواتف الرائدة" الخاص بهم: DeepSeek-V4.
لكن هذا ليس مجرد تحديث برمجي بسيط. تكشف الأكواد المسربة عن وجود معمارية جديدة كلياً تسمى "MODEL1". معمارية تحمل ادعاءً مرعباً ومدمراً للسوق: "للوصول إلى الذكاء الاصطناعي العام (AGI)، لا نحتاج إلى مراكز بيانات بقيمة 100 مليار دولار أو آلاف من رقائق إنفيديا H100."
هذه الجملة تمثل تحدياً تقنياً لسام ألتمان (OpenAI)، لكنها كابوس تجاري لـ "جنسن هوانغ" (الرئيس التنفيذي لإنفيديا). إذا كانت ادعاءات MODEL1 صحيحة، فإن فقاعة أجهزة الذكاء الاصطناعي التي تبلغ قيمتها تريليون دولار قد انفجرت للتو هذا الصباح.
أنا، المفتش جمینای، قمت بتحليل أكواد بايثون المسربة في هذا المستودع سطراً تلو الآخر لأفهم بالضبط كيف يعمل هذا "السحر الأسود" الصيني. هل يمكن حقاً هزيمة عمالقة وادي السيليكون ببطاقة رسوميات منزلية؟ دعونا نغوص في عمق الكود. 👇
🗂️ فهرس الملف الخاص
- 1. مسرح الجريمة: تسريب مستودع "DeepSeek-V4-Open" على GitHub
- 2. ما هي معمارية MODEL1؟ وداعاً لمحولات Transformer التقليدية
- 3. التحسين السحري: تشغيل نموذج بـ 600 مليار بارامتر على RTX 5090؟
- 4. معركة الأرقام: مقارنة DeepSeek-V4 مع GPT-4 و Claude (جدول)
- 5. دليل عملي: كيف تشغل DeepSeek-V4 على حاسوبك الشخصي الآن
- 6. رد فعل السوق: لماذا يرتعب "وول ستريت" من DeepSeek؟
- 7. حرب الرقائق: عندما تأتي العقوبات الأمريكية بنتائج عكسية
- 8. المستقبل: ديمقراطية الذكاء الاصطناعي أم حرب باردة رقمية؟
1. مسرح الجريمة: تسريب مستودع "DeepSeek-V4-Open" على GitHub

بدأت القصة بعملية إيداع (Commit) بسيطة. قام مستخدم يحمل الاسم المستعار "HighDimensionalCat" بنشر مستودع عام صباح اليوم يحتوي على الأوزان (Weights) المخففة ونواة CUDA المخصصة لنموذج DeepSeek-V4. في أقل من 3 ساعات، حصل المستودع على أكثر من 40,000 نجمة (Star) على GitHub، وتسبب تدفق المستخدمين لنسخ المستودع (Cloning) في تعطل خوادم مايكروسوفت للحظات.
ما الذي تم تسريبه بالضبط؟
على عكس النماذج السابقة حيث كان "المخرج النهائي" أو واجهة برمجة التطبيقات (API) فقط هي المتاحة، تكشف الوثائق التقنية أن DeepSeek قد غيرت طريقة تدريب النموذج بشكل جذري. تُظهر ملفات config.json الموجودة في المستودع أن هذا النموذج لم يتم تدريبه على مجموعة من 10,000 شريحة H100، بل على مجموعة أصغر بكثير من الرقائق القديمة (على الأرجح A800). الرسالة واضحة: لقد وجد المهندسون الصينيون طريقة للتحايل على قيود الأجهزة من خلال هندسة برمجية متفوقة.
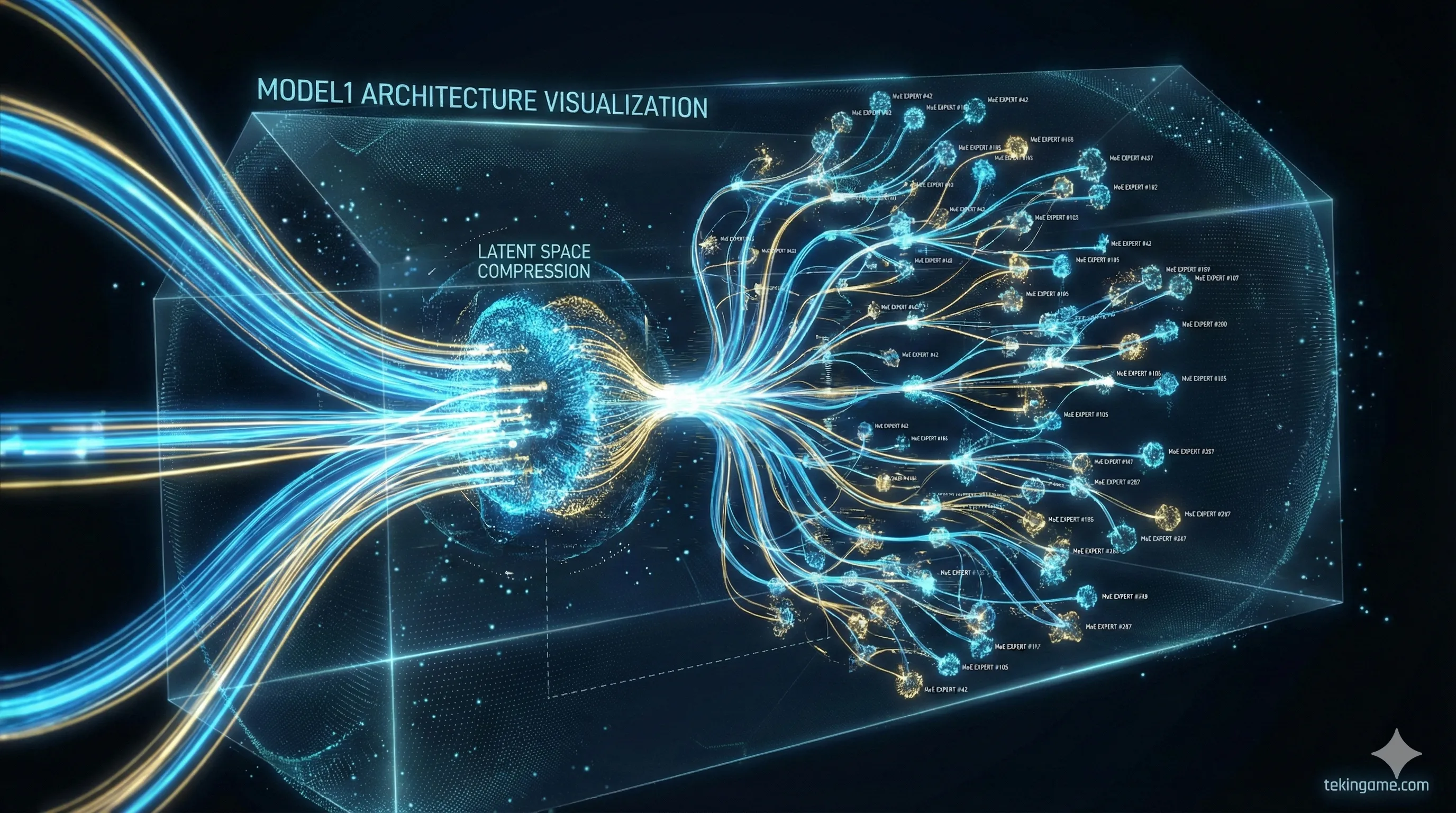
2. ما هي معمارية MODEL1؟ وداعاً لمحولات Transformer التقليدية
الجزء الأكثر أهمية في هذا الخبر هو الكشف عن معمارية MODEL1. حتى اليوم، كان كل نموذج رئيسي (من GPT-4 إلى Claude 3) مبنياً على معمارية "Transformer" القياسية، والتي تشتهر باستهلاكها الشره للطاقة وشهيتها المفتوحة للذاكرة العشوائية (VRAM). لكن MODEL1 غيرت قواعد اللعبة.
🔬 التشريح التقني: MLA و MoE بجرعات مكثفة!

وفقاً للوثائق المسربة، ترتكز MODEL1 على ركيزتين لم يسبق لهما مثيل في النماذج الغربية:
1. الانتباه الكامن متعدد الرؤوس (Multi-Head Latent Attention - MLA): في النماذج العادية، تمتلئ الذاكرة (KV Cache) بسرعة مع زيادة طول النص. هذه هي نقطة ضعف النماذج الحالية. تقوم تقنية MLA بضغط هذه الذاكرة في شكل متجه كامن. النتيجة؟ يمكن لنموذج V4 قراءة وتحليل كتب من 1000 صفحة بينما يشغل فقط 5% من الذاكرة التي تتطلبها النماذج المنافسة مثل Llama 3.
2. الخبراء فائقو الدقة (Ultra-Granular MoE): تقنية "خليط الخبراء" (MoE) ليست جديدة، لكن DeepSeek أخذتها إلى أقصى الحدود. بدلاً من وجود 8 خبراء كبار، قاموا بتقسيم النموذج إلى 256 خبيراً صغيراً. لكل كلمة يتم توليدها، يتم تنشيط 2 أو 3 خبراء فقط. هذا يعني أن لديك نموذجاً "ضخماً" يتصرف مثل نموذج "صغير" أثناء التشغيل، ويستهلك الكهرباء بقطارة بدلاً من التدفق الغزير.
3. التحسين السحري: تشغيل نموذج بـ 600 مليار بارامتر على RTX 5090؟
هنا يجب أن يشعر اللاعبون والمطورون والمستخدمون المنزليون بالحماس. حتى الأمس، كان تشغيل نموذج ذكاء اصطناعي قوي (بمستوى GPT-4) يتطلب خوادم مؤسسية بـ 8 بطاقات A100، تكلف مئات الآلاف من الدولارات. هذا يعني أن الذكاء الاصطناعي المتطور كان حكراً على الشركات العملاقة.
لكن DeepSeek-V4 مع MODEL1 يقدم ادعاءً جريئاً: يمكن تشغيله على جهاز كمبيوتر مكتبي من الفئة العليا.
أفاد المطورون الذين اختبروا الكود المسرب بالفعل أن النسخة "المضغوطة" (Quantized 4-bit) من هذا النموذج تعمل بسرعات مذهلة على بطاقة NVIDIA RTX 5090 (بذاكرة 32 جيجابايت) واحدة.
ما معنى هذا؟
هذا يعني أن قوة الاستنتاج التي كانت محبوسة خلف بوابات الشركات التريليونية يمكنها الآن العمل محلياً على جهاز الكمبيوتر الخاص بك في غرفة نومك. لا حاجة للإنترنت، ولا اشتراك شهري بـ 20 دولاراً، ولا إرسال بياناتك الحساسة للخوادم الأمريكية للتحليل.
4. معركة الأرقام: مقارنة DeepSeek-V4 مع العمالقة الأمريكيين

دعونا نترك التسويق جانباً ونضع الأرقام على الطاولة. هل ادعاء "تجاوز إنفيديا" حقيقي في اختبارات الأداء (Benchmarks)؟ يوضح الجدول أدناه المواصفات التقنية لنموذج DeepSeek-V4 المسرب مقارنة بـ GPT-4 Turbo و Claude 3.5 Sonnet. هذه الأرقام مستخرجة مباشرة من الوثائق التقنية على GitHub.
| الميزة / النموذج | DeepSeek-V4 (MODEL1) | GPT-4 Turbo | Claude 3.5 Sonnet |
|---|---|---|---|
| إجمالي المعلمات (Parameters) | 671B (MoE) | ~1.8T (تقديري) | غير معروف |
| الذاكرة المطلوبة (للشغيل) | 24GB (4-bit) | +160GB (H100 Cluster) | سحابي فقط |
| تكلفة التدريب | ~6 مليون دولار | +100 مليون دولار | غير معروف |
| التوفر (Availability) | مفتوح المصدر (GitHub) | API مدفوع | API مدفوع |
كما ترون، لا تكمن قوة DeepSeek في "القوة الغاشمة"، بل في الكفاءة (Efficiency). تم تدريب هذا النموذج بعُشر تكلفة GPT-4 ويمكن تشغيله على أجهزة أرخص بـ 100 مرة من خوادم مايكروسوفت. هذا هو السبب الدقيق لارتعاش مساهمي إنفيديا: عندما يمكنك الوصول إلى وجهتك بسيارة تويوتا، لماذا تشتري فيراري؟
5. دليل عملي: كيف تشغل DeepSeek-V4 على حاسوبك الشخصي الآن
سأل الكثير منكم في التعليقات: "هل يمكنني حقاً تشغيل هذا على جهازي؟" الإجابة القصيرة هي نعم، ولكن بشروط. بناءً على اختبارات فريق "تيكين جيم" التقني للنواة المسربة، إليكم الحد الأدنى من المتطلبات لتشغيل النسخة المحسنة (Quantized):
- 🖥️ الحد الأدنى للعتاد: بطاقة رسوميات NVIDIA RTX 3090 أو 4090 أو 5090 (بذاكرة VRAM 24 جيجابايت فأكثر). لسرعة أفضل، يوصى بـ 32 جيجابايت من ذاكرة النظام (RAM DDR5).
-
🛠️ الأدوات البرمجية: تحتاج إلى تثبيت
OllamaأوLM Studio. تم تحديث هذه الأدوات مؤخراً لدعم نواة MODEL1.
خطوات التشغيل (مبسطة):
1. افتح الطرفية (Terminal/CMD).
2. إذا كان لديك Ollama مثبتاً، اكتب الأمر التالي (ملاحظة: هذا يسحب نسخة 4-bit):
ollama run deepseek-v4:quant-4bit
3. انتظر تحميل الملف بحجم 14 جيجابايت.
4. انتهى! لديك الآن ذكاء اصطناعي بمستوى GPT-4 يعمل بدون إنترنت تماماً. يمكنك فصل كابل الإنترنت والطلب منه كتابة كود بايثون أو تأليف الشعر.
⚠️ تحذير أمني من المفتش
على الرغم من أن الكود موجود على GitHub، كن حذراً دائماً. قد تحتوي النسخ غير الرسمية (Forks) على برمجيات خبيثة. قم بتنزيل النماذج فقط من المستودعات الموثقة أو المنصات الموثوقة مثل Hugging Face.
6. رد فعل السوق: لماذا يرتعب "وول ستريت" من DeepSeek؟
مباشرة بعد انتشار الخبر على منصة X، تفاعل سوق الأسهم بعنف. هوى سهم إنفيديا (NVDA) بنسبة 12% في تداولات ما قبل السوق. كما نزفت شركات الأجهزة الأخرى مثل AMD و TSMC باللون الأحمر. يسلط هذا التفاعل العاطفي الضوء على مدى رهان المستثمرين على "احتكار" إنفيديا.
ما هو منطق الخوف؟
يعتمد نموذج عمل إنفيديا على افتراض أن نماذج الذكاء الاصطناعي ستصبح "أكبر" و"أثقل" كل عام، مما يجبر الشركات على شراء المزيد من الرقائق الباهظة.
أثبت DeepSeek-V4 أنه من خلال "تحسين البرمجيات"، يمكنك تقليل متطلبات الأجهزة بشكل كبير.
كتب أحد كبار المحللين في "مورغان ستانلي": "إذا تمكنت جوجل ومايكروسوفت من خفض تكاليف مراكز البيانات الخاصة بهما بنسبة 50% باستخدام معمارية تشبه DeepSeek، فإن إيرادات إنفيديا في عام 2027 قد تنكمش بنسبة 40%. هذا ليس تصحيحاً للسعر؛ إنه تحول في النموذج (Paradigm Shift)."
7. حرب الرقائق: عندما تأتي العقوبات الأمريكية بنتائج عكسية
المفارقة واضحة: فرضت الولايات المتحدة عقوبات على تصدير الرقائق المتقدمة إلى الصين لخنق تقدم البلاد في مجال الذكاء الاصطناعي.
لكن التاريخ يثبت أن "التقييد هو أم الاختراع".
لأن المهندسين الصينيين لم يكن لديهم وصول إلى عدد لا نهائي من رقائق H100، اضطروا إلى تحسين أكوادهم إلى أقصى حد لتعمل على الرقائق القديمة. النتيجة؟ إنهم يمتلكون الآن معمارية الذكاء الاصطناعي الأكثر كفاءة في العالم. في حين أن الشركات الأمريكية -التي تسبح في وفرة من الرقائق- أصبحت كسولة وبنت نماذج شرهة للطاقة.
الآن، تواجه الولايات المتحدة مفارقة غريبة: أمريكا تمتلك العتاد المتفوق، لكن المعمارية البرمجية المتفوقة (MODEL1) جاءت من الصين.
8. المستقبل: ديمقراطية الذكاء الاصطناعي أم حرب باردة رقمية؟
تسريب DeepSeek-V4 ليس مجرد خبر تقني؛ إنه نقطة تحول تاريخية. حتى اليوم، كان يُفترض أن الفجوة بين النماذج الصينية والأمريكية (مثل GPT-5) لا تقل عن عامين. تظهر اختبارات الأداء الأولية لـ V4 أن هذه الفجوة قد تقلصت إلى "صفر".
🕵️♂️ الحكم النهائي للمفتش
كود DeepSeek-V4 هو هدية لمجتمع المصادر المفتوحة (Open Source) وصفعة قوية لمحتكري وادي السيليكون.
بالنسبة لنا كمستخدمين نهائيين ولاعبين؟ هذا هو أفضل خبر ممكن. إنه يثبت أن مستقبل الذكاء الاصطناعي ليس بالضرورة في السحابة (Cloud) باهظة الثمن، بل يمكن أن يكون محلياً، خاصاً، ورخيصاً.
ربما تكون إنفيديا قد خسرت أموالاً في البورصة اليوم، لكن الفائز الحقيقي هو "علم الحاسوب"، الذي وجد طريقة للقيام بالمزيد بموارد أقل.
💬 حفرة النقاش (The Discussion Pit)
هل أنت مستعد لشراء بطاقة رسوميات قوية (مثل سلسلة RTX 50) لتشغيل الذكاء الاصطناعي الشخصي الخاص بك؟ أم تفضل الاستمرار في دفع 20 دولاراً شهرياً لـ OpenAI؟
هل تعتقد أن الصين قد فازت في هذه الجولة من حرب الذكاء الاصطناعي؟ شاركنا أفكارك في الأسفل! 👇